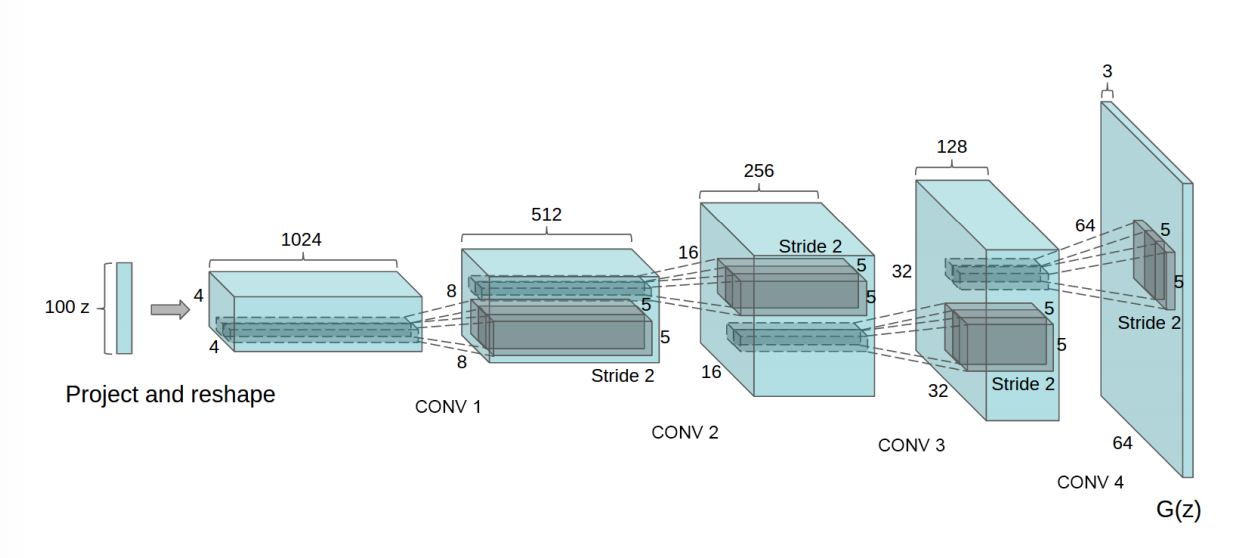
网络结构
在DCGAN(本文)或者普通GAN的基础上,将交叉熵损失改为均方误差损失,就得到了LSGAN
LSGAN是对之前两种GAN的优化,因为当生成器生成的数据分布$P_G$与数据的真实分布$P_{data}$不重叠时,JS散度永远都是log2,从而导致生成器难以更新,见下图


导入相关函数
1
2
3
4
5
| import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import matplotlib.pyplot as plt
import numpy as np
|
准备数据
1
| (train_images,_),(_,_)=tf.keras.datasets.mnist.load_data()
|
(60000, 28, 28)
dtype('uint8')
1
| train_images=train_images.reshape(train_images.shape[0],28,28,1).astype('float32')
|
(60000, 28, 28, 1)
dtype('float32')
1
| train_images=(train_images-127.5)/127.1
|
1
2
| BATCH_SIZE=256
BUFFER_SIZE=60000
|
1
| datasets=tf.data.Dataset.from_tensor_slices(train_images)
|
<TensorSliceDataset shapes: (28, 28, 1), types: tf.float32>
1
| datasets=datasets.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)
|
<BatchDataset shapes: (None, 28, 28, 1), types: tf.float32>
搭建生成器网络和判别器网络
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| def generator_model():
model=tf.keras.Sequential()
model.add(layers.Dense(7*7*256,use_bias=False,input_shape=(100,)))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Reshape((7,7,256)))
model.add(layers.Conv2DTranspose(128,(5,5),strides=(1,1),padding='same',use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(64,(5,5),strides=(2,2),padding='same',use_bias=False))
model.add(layers.BatchNormalization())
model.add(layers.LeakyReLU())
model.add(layers.Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
return model
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| def discriminator_model():
model=tf.keras.Sequential()
model.add(layers.Conv2D(64,(5,5),strides=(2,2),padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Conv2D(128,(5,5),strides=(2,2),padding='same'))
model.add(layers.LeakyReLU())
model.add(layers.Dropout(0.3))
model.add(layers.Flatten())
model.add(layers.Dense(1))
return model
|
定义损失函数
1
2
3
4
5
|
def discriminator_loss(real_out,fake_out):
real_loss=tf.reduce_sum(tf.square(real_out-1))/2
fake_loss=tf.reduce_sum(tf.square(fake_out-0))/2
return real_loss+fake_loss
|
1
2
3
| def generator_loss(fake_out):
fake_loss=tf.reduce_sum(tf.square(fake_out-1))/2
return fake_loss
|
定义优化器
1
2
| generator_opt=tf.keras.optimizers.Adam(1e-4)
discriminator_opt=tf.keras.optimizers.Adam(1e-4)
|
设置超参数,实例化生成器和判别器
1
2
3
4
5
6
7
| EPOCHS=100
noise_dim=100
num_example_to_generate=16
seed=tf.random.normal([num_example_to_generate,noise_dim])
generator=generator_model()
discriminator=discriminator_model()
|
定义每个batch训练的过程
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| def train_step(images_one_batch):
noise=tf.random.normal([num_example_to_generate,noise_dim])
with tf.GradientTape() as gen_tape,tf.GradientTape() as disc_tape:
real_out=discriminator(images_one_batch,training=True)
gen_image=generator(noise,training=True)
fake_out=discriminator(gen_image,training=True)
gen_loss=generator_loss(fake_out)
disc_loss=discriminator_loss(real_out,fake_out)
gradient_gen=gen_tape.gradient(gen_loss,generator.trainable_variables)
gradient_disc=disc_tape.gradient(disc_loss,discriminator.trainable_variables)
generator_opt.apply_gradients(zip(gradient_gen,generator.trainable_variables))
discriminator_opt.apply_gradients(zip(gradient_disc,discriminator.trainable_variables))
|
定义生成图片展示的函数
1
2
3
4
5
6
7
8
9
|
def generate_plot_image(gen_model,test_noise):
pre_images=gen_model(test_noise,training=False)
fig=plt.figure(figsize=(4,4))
for i in range(pre_images.shape[0]):
plt.subplot(4,4,i+1)
plt.imshow((pre_images[i,:,:,0]+1)/2,cmap='gray')
plt.axis('off')
plt.show()
|
定义训练函数
1
2
3
4
5
| def train(dataset,epochs):
for epoch in range(epochs):
for image_batch in dataset:
train_step(image_batch)
generate_plot_image(generator,seed)
|
开始训练
漫长的等待过后,最终的生成图片如下: