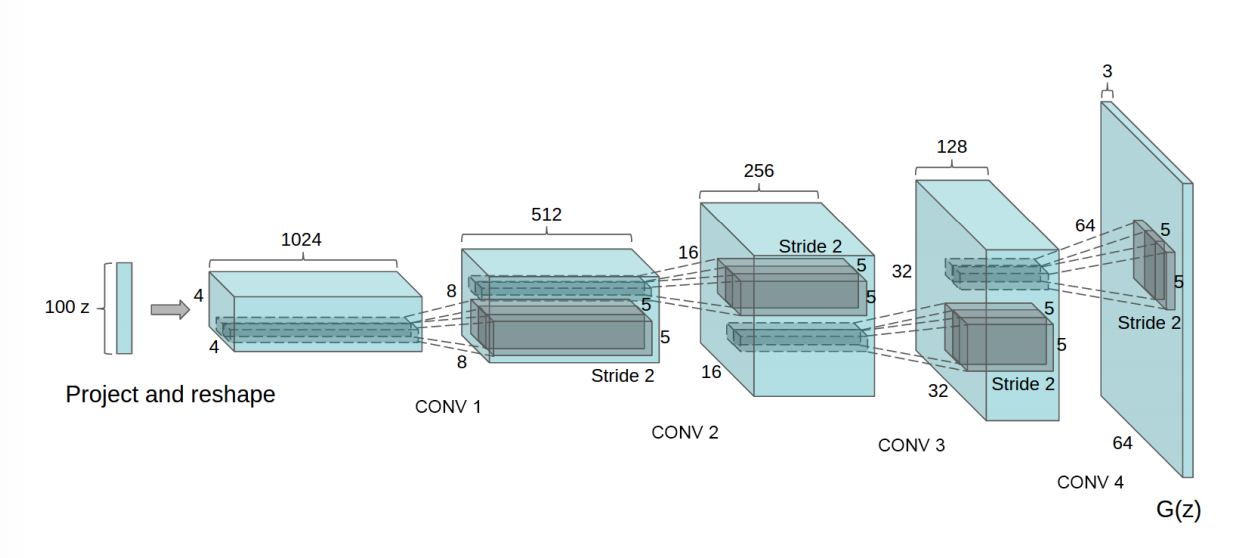
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
|
class DataLoader():
def __init__(self, dataset_name, img_res=(128, 128)):
self.dataset_name = dataset_name
self.img_res = img_res
def load_data(self, domain, batch_size=1, is_testing=False):
data_type = "train%s" % domain if not is_testing else "test%s" % domain
path = glob('/home/fanxi/Desktop/dataset/%s/%s/*' % (self.dataset_name, data_type))
batch_images = np.random.choice(path, size=batch_size)
imgs = []
for img_path in batch_images:
img = self.imread(img_path)
if not is_testing:
img = resize(img, self.img_res)
if np.random.random() > 0.5:
img = np.fliplr(img)
else:
img = resize(img, self.img_res)
imgs.append(img)
imgs = np.array(imgs)/127.5 - 1.
return imgs
def load_batch(self, batch_size=1, is_testing=False):
data_type = "train" if not is_testing else "val"
path_A = glob('/home/fanxi/Desktop/dataset/%s/%sA/*' % (self.dataset_name, data_type))
path_B = glob('/home/fanxi/Desktop/dataset/%s/%sB/*' % (self.dataset_name, data_type))
self.n_batches = int(min(len(path_A), len(path_B)) / batch_size)
total_samples = self.n_batches * batch_size
path_A = np.random.choice(path_A, total_samples, replace=False)
path_B = np.random.choice(path_B, total_samples, replace=False)
for i in range(self.n_batches-1):
batch_A = path_A[i*batch_size:(i+1)*batch_size]
batch_B = path_B[i*batch_size:(i+1)*batch_size]
imgs_A, imgs_B = [], []
for img_A, img_B in zip(batch_A, batch_B):
img_A = self.imread(img_A)
img_B = self.imread(img_B)
img_A = resize(img_A, self.img_res)
img_B = resize(img_B, self.img_res)
if not is_testing and np.random.random() > 0.5:
img_A = np.fliplr(img_A)
img_B = np.fliplr(img_B)
imgs_A.append(img_A)
imgs_B.append(img_B)
imgs_A = np.array(imgs_A)/127.5 - 1.
imgs_B = np.array(imgs_B)/127.5 - 1.
yield imgs_A, imgs_B
def load_img(self, path):
img = self.imread(path)
img = resize(img, self.img_res)
img = img/127.5 - 1.
return img[np.newaxis, :, :, :]
def imread(self, path):
return imageio.imread(path).astype(np.float)
|