data=DataSet() plt.scatter(data.feature[:,0],data.feature[:,1],c=data.target) for i inrange(len(data.feature)): plt.text(data.feature[i,0], data.feature[i,1],data.target[i], fontsize=8, color = "b") plt.show()
defrun(self,new_sample_feature): #对于每一个样本的特征 all_dists=[] for i, sample_feature inenumerate(self.samples_feature): #1.分别计算新的样本与训练集中所有样本之间的距离 dist=self.cal_dist(sample_feature,new_sample_feature) all_dists.append((dist,self.samples_target[i])) #2.按照距离从小到大排序 sorted_dist_with_target=sorted(all_dists,key=lambda x:x[0]) #3.选取距离新样本最近的k个 top_k=sorted_dist_with_target[0:self.k] #4.统计这k个样本中大多数样本所属类别 dic={} for item in top_k: if item[1] in dic: dic[item[1]]+=1 else: dic[item[1]]=1 result=sorted(dic.items(),key=lambda x:x[1])[-1][0] return result
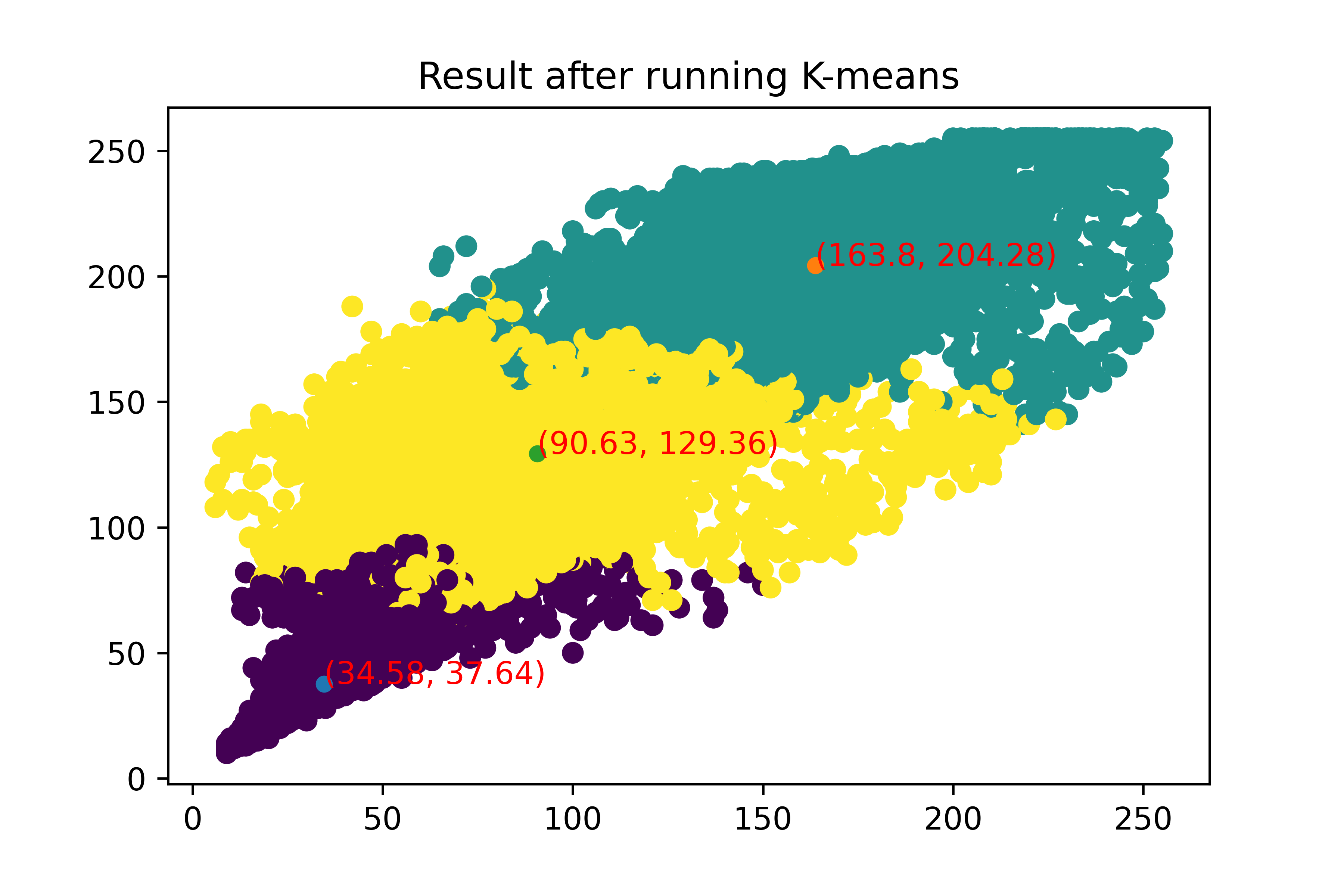
data=DataSet() #训练数据 plt.scatter(data.feature[:,0],data.feature[:,1],c=data.target) for i inrange(len(data.feature)): plt.text(data.feature[i,0], data.feature[i,1],data.target[i], fontsize=8, color = "b") #测试数据 plt.scatter(test_samples_feature[:,0],test_samples_feature[:,1]) for i inrange(len(test_samples_feature)): plt.text(test_samples_feature[i,0], test_samples_feature[i,1], 'sample{}:\n'.format(i+1)+str((test_samples_feature[i,0],test_samples_feature[i,1])), fontsize=10, color = "r") plt.show()