目录抢先看 :
赛题背景 随着电子商务与全球经济、社会各领域的深度融合,电子商务已成为我国经济数字化转型巨大动能。庞大的用户基数,飞速发展的移动互联网行业,balabalabala……
本次比赛提供消费门户网站“什么值得买”2021年1月-2021年5月真实平台文章数据约100万条,旨在根据文章前两个小时信息,利用当前先进的机器学习算法进行智能预估第三到十五小时的文章产品销量,及时发现有潜力的爆款商品,将业务目标转化成商品销量预测,为用户提供更好的产品推荐并提升平台收益。
赛题地址: https://www.automl.ai/competitions/19#home
数据介绍 赛题数据包含以下部分:
1 2 3 4 - train.csv #训练数据 - test.csv #测试数据 - sample_submission.csv #样例预测文件 - sample_submission.csv.zip #样例提交文件
数据集所含字段如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 字段名称 字段类型 字段说明 article_id int 文章id date int 当前样本是第几天的 price int 文章商品价格 price_diff int 与上一次价格差 author int 文章作者 level1 int 文章一级品类 level2 int 文章二级品类 level3 int 文章三级品类 level4 int 文章四级品类 brand int 文章品牌 mall int 商城,比如京东、天猫等 url int 文章url id,对应第三方链接,等同第三方sku baike_id_1h int 文章前1 个小时对应的商品id baike_id_2h int 文章前2 个小时对应的商品id comments_1h int 文章前1 个小时评论数 comments_2h int 文章前2 个小时评论数 zhi_1h int 文章前1 个小时值数 zhi_2h int 文章前2 个小时值数 buzhi_1h int 文章前1 个小时不值数 buzhi_2h int 文章前2 个小时不值数 favorite_1h int 文章前1 个小时收藏数 favorite_2h int 文章前2 个小时收藏数 orders_1h int 文章发布后前1 个小时的销量 orders_2h int 文章发布后前2 个小时的销量 orders_3h_15h int 文章发布后3 个小时到15 个小时内的销量,训练集会直接提供,测试集为空,需要预测
评价指标 本次比赛使用均方误差(Mean Squared Erroe, MSE)作为评价指标,越低越好:
数据探索 导入用到的Python第三方库 :
1 2 3 4 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as sns
读取训练集和测试集 :
1 2 train_df=pd.read_csv('train.csv' ) test_df=pd.read_csv('test.csv' )
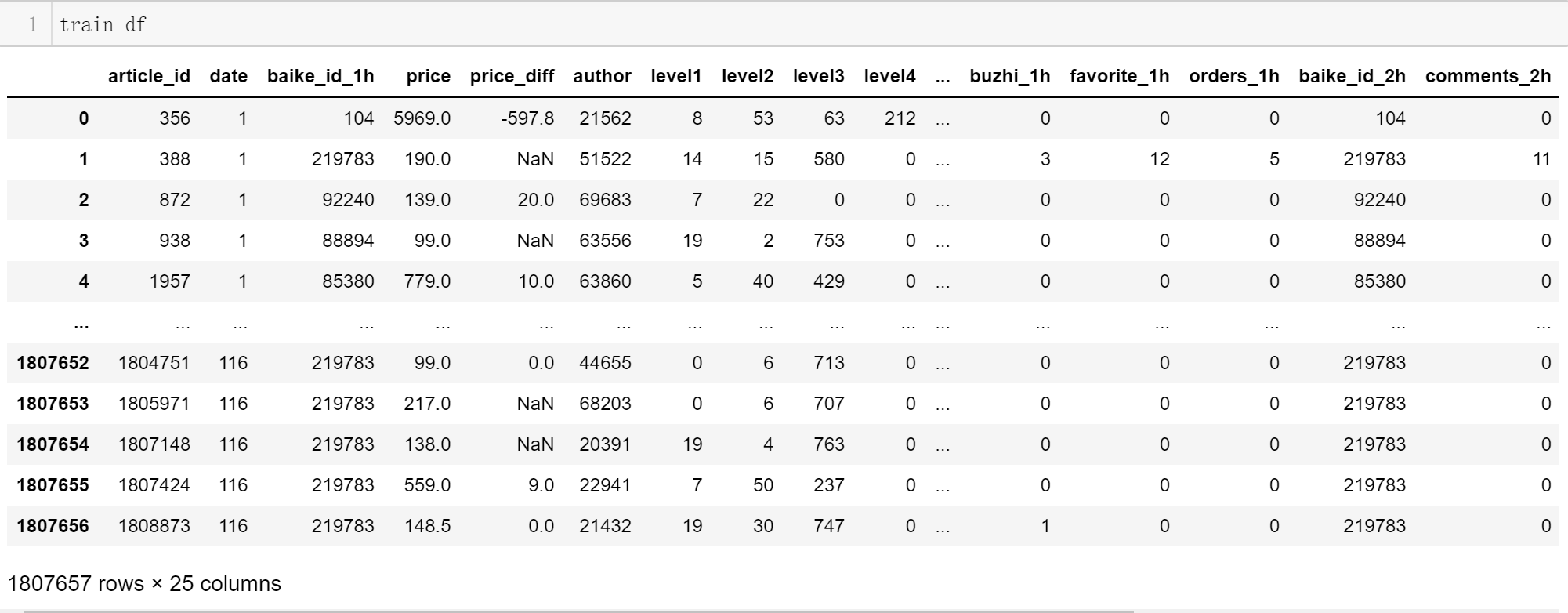
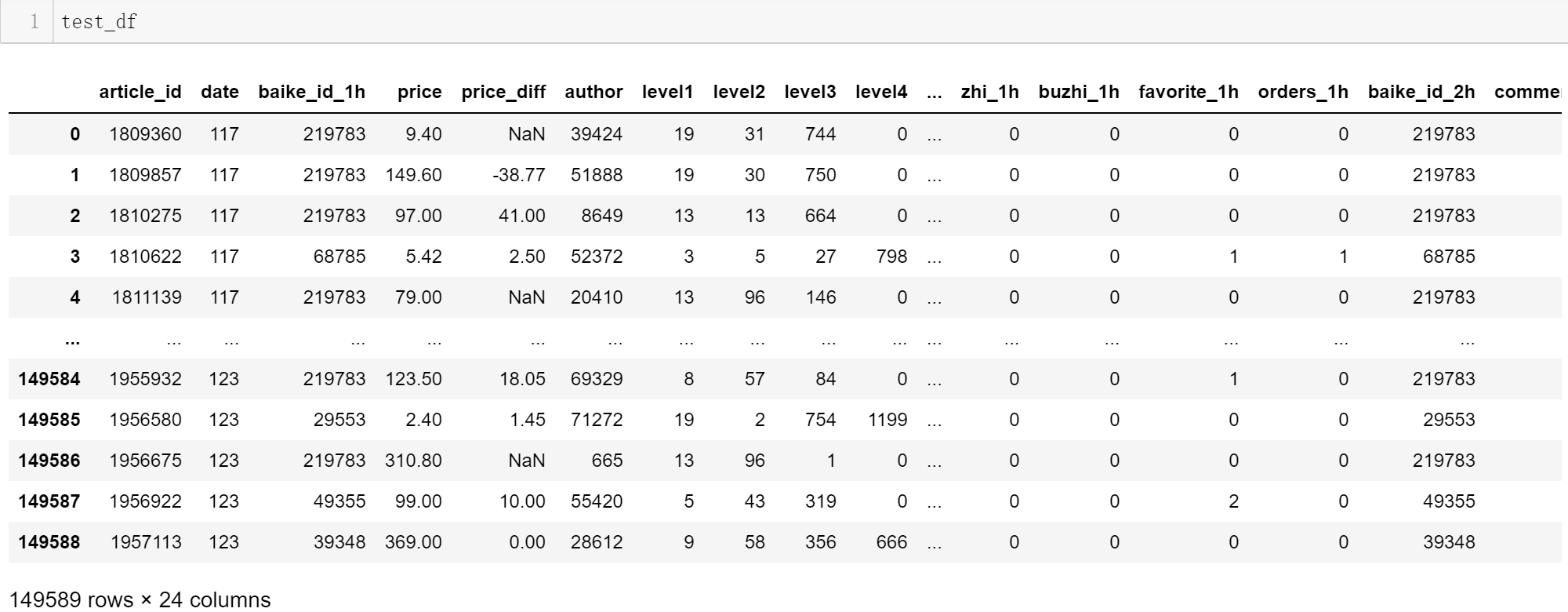
总共的原始特征数是24,训练集包含对应的标签,因此共25列。
训练集有180万+条数据,测试集有14万+条数据。
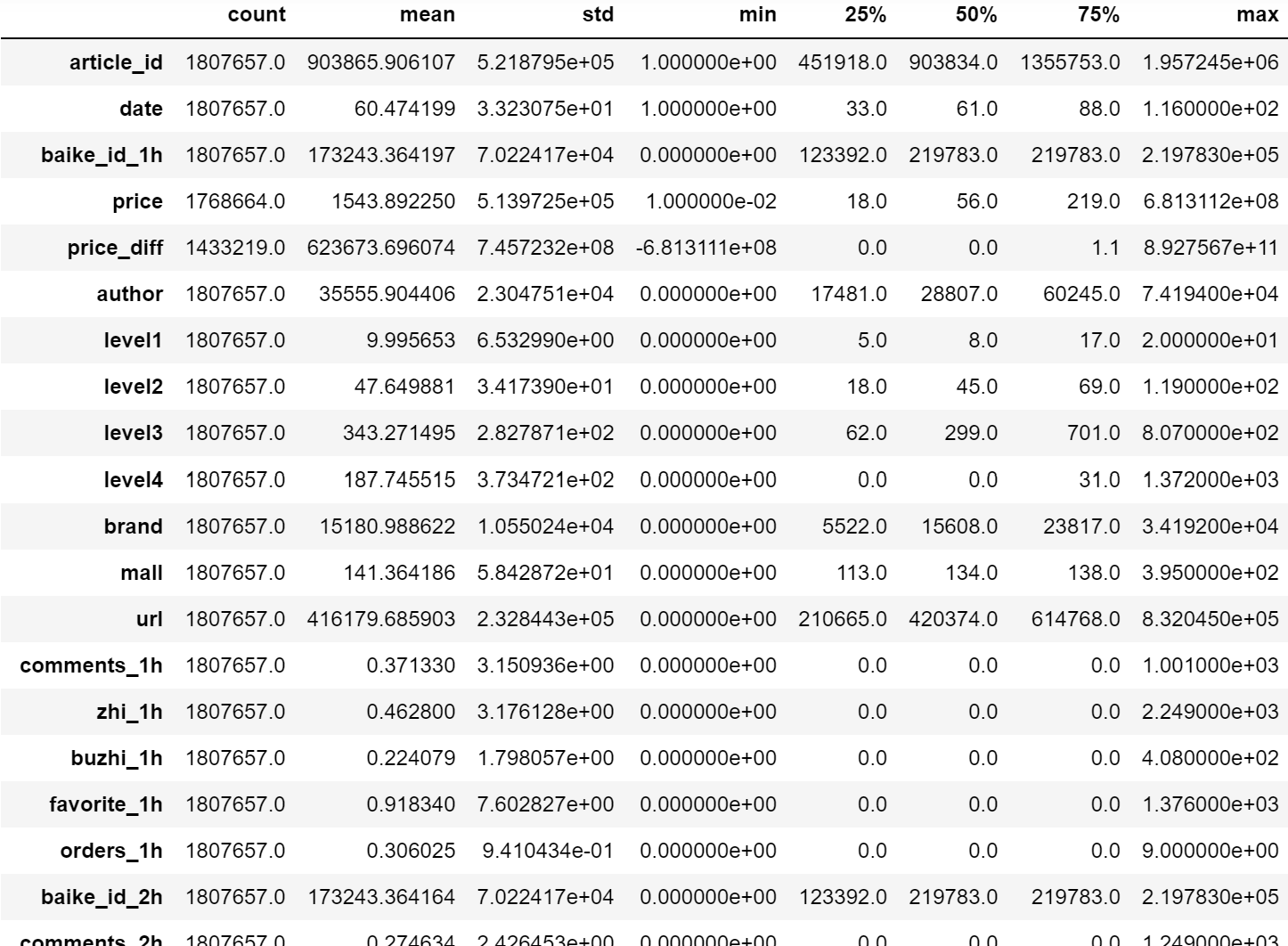
查看常用统计量
检查是否存在缺失值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 article_id 0 date 0 baike_id_1h 0 price 38993 price_diff 374438 author 0 level1 0 level2 0 level3 0 level4 0 brand 0 mall 0 url 0 comments_1h 0 zhi_1h 0 buzhi_1h 0 favorite_1h 0 orders_1h 0 baike_id_2h 0 comments_2h 0 zhi_2h 0 buzhi_2h 0 favorite_2h 0 orders_2h 0 orders_3h_15h 0 dtype: int64
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 article_id 0 date 0 baike_id_1h 0 price 4066 price_diff 38944 author 0 level1 0 level2 0 level3 0 level4 0 brand 0 mall 0 url 0 comments_1h 0 zhi_1h 0 buzhi_1h 0 favorite_1h 0 orders_1h 0 baike_id_2h 0 comments_2h 0 zhi_2h 0 buzhi_2h 0 favorite_2h 0 orders_2h 0 dtype: int64
price 和price_diff列有缺失值。因此在建模时,若选用非树模型,一般是需要手动处理缺失值的,可以用诸如该特征的均值,中位数等统计量,或者插值的方式进行缺失值填补,或者在数据量足够大的情况下(比如本赛题数据量足够大)直接简单的删除缺失值对应行。而若选用树模型,则可以自行决定是否手动处理缺失值(树模型可以自动处理缺失值)。
查看特征之间的相关性
1 2 3 train_corr=train_df.drop(['article_id' ],axis=1 ).corr() ax=plt.subplots(figsize=(20 ,16 )) ax=sns.heatmap(train_corr,vmax=.8 ,square=True ,annot=True )
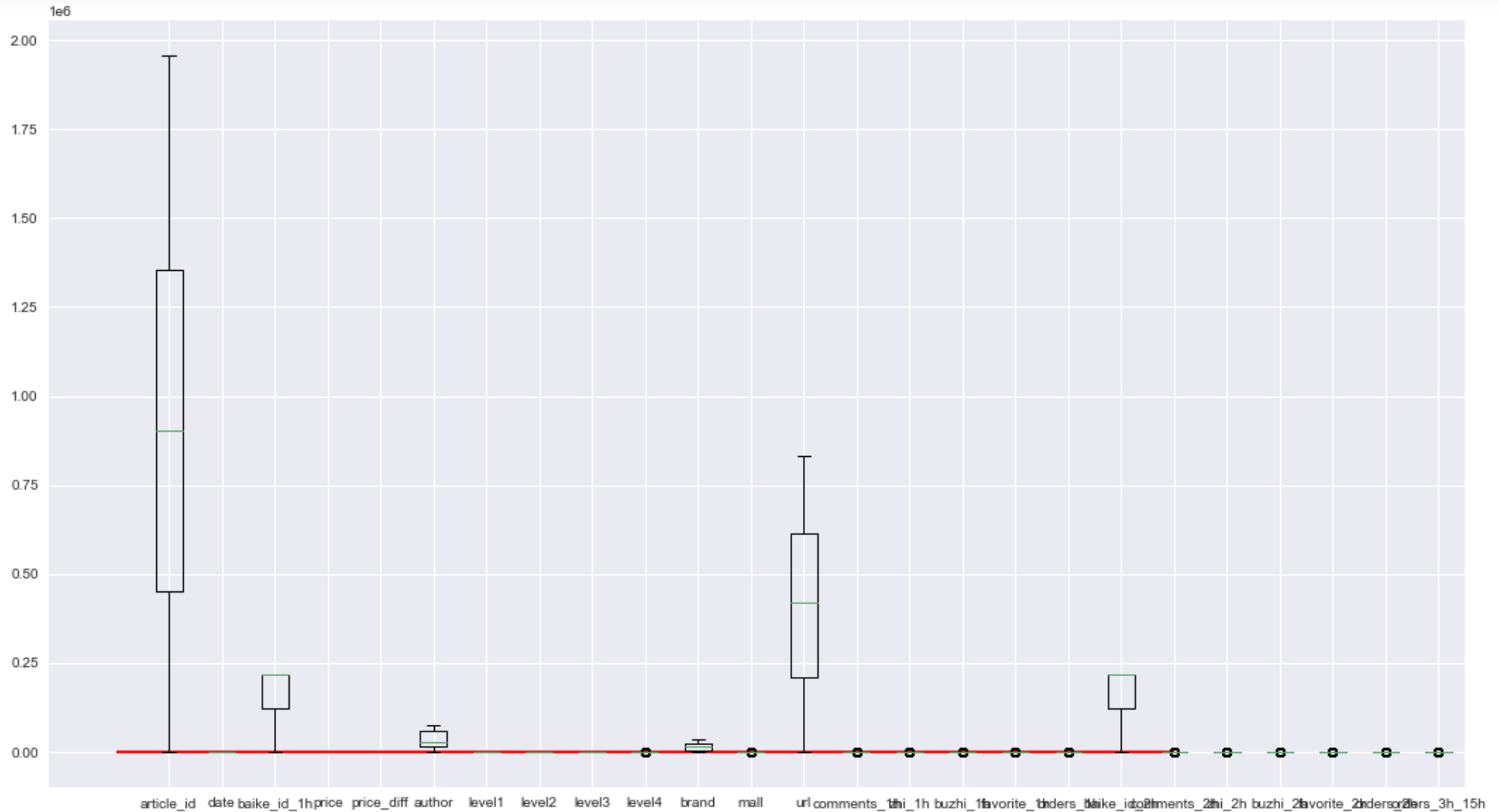
箱线图查看训练集特征的分散情况
1 2 3 4 plt.figure(figsize=(18 ,10 )) plt.boxplot(x=train_df.values,labels=train_df.columns) plt.hlines([-7.5 ,7.5 ],0 ,20 ,color='r' ) plt.show()
查看训练集特征取值情况
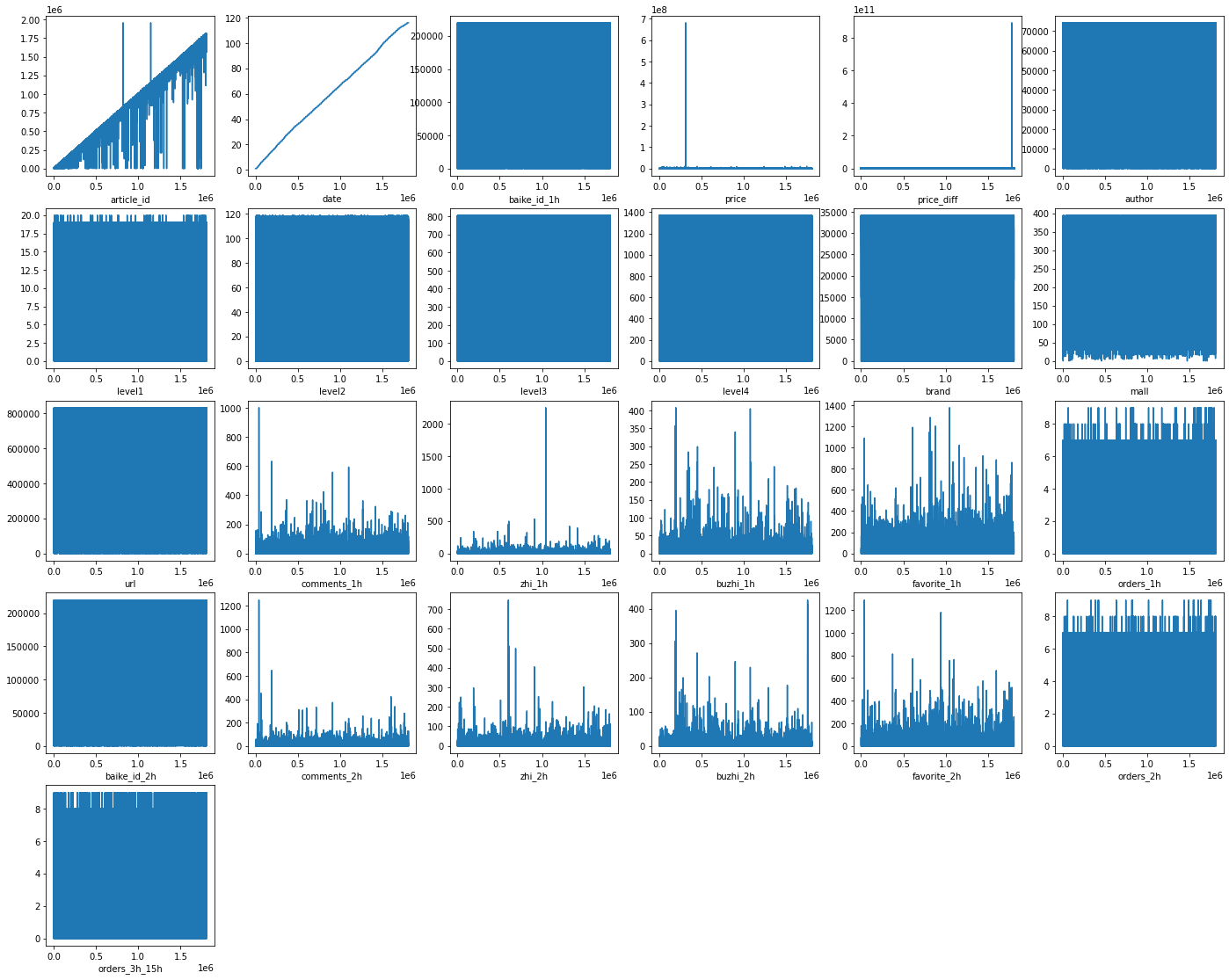
折线图:
1 2 3 4 5 6 7 8 9 10 dist_cols=6 dist_rows=len (test_df.columns) plt.figure(figsize=(4 *dist_cols,4 *dist_rows)) i=1 for col in train_df.columns: ax=plt.subplot(dist_rows,dist_cols,i) ax=plt.plot(train_df[col]) plt.xlabel(col) i+=1 plt.show()
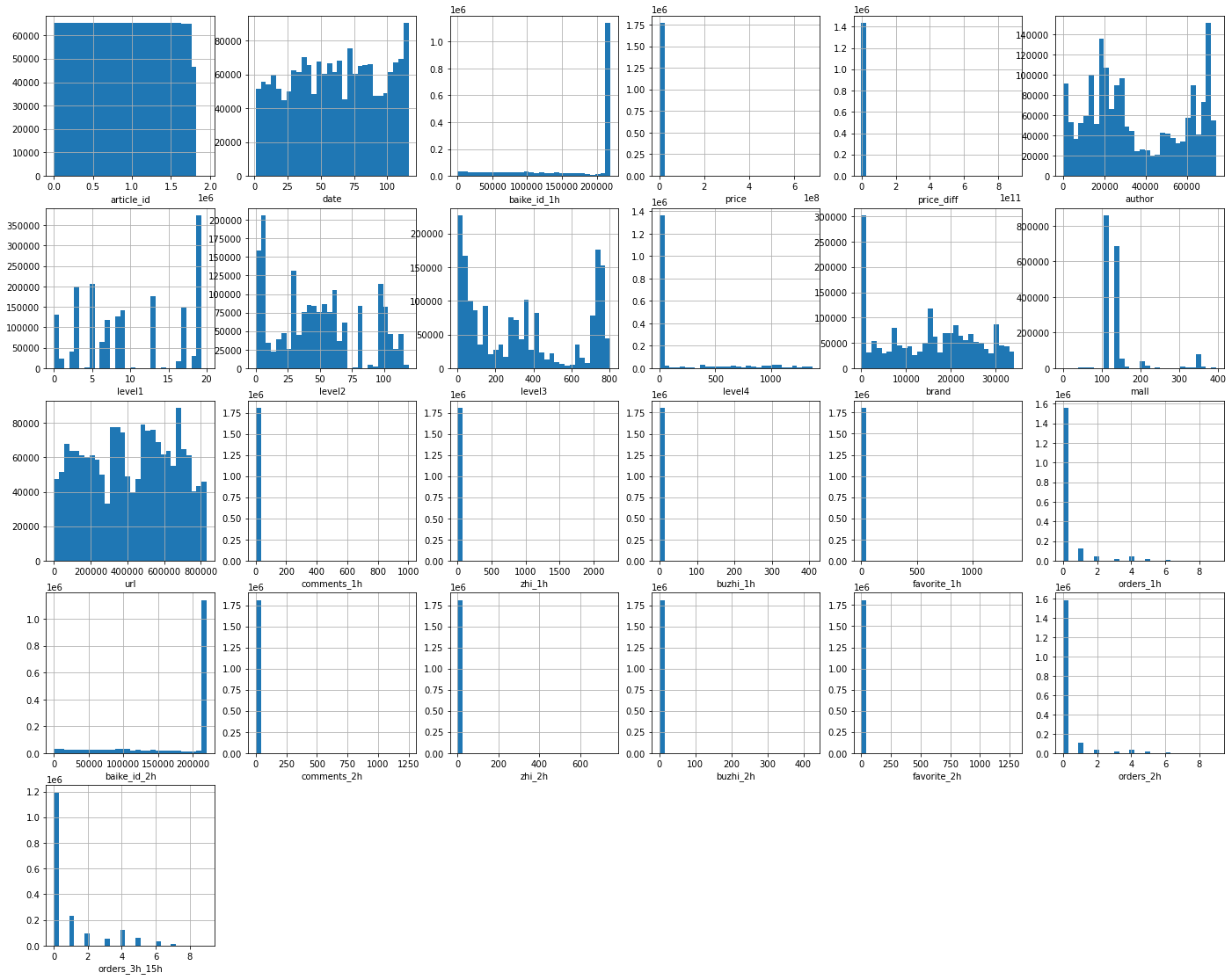
直方图:
1 2 3 4 5 6 7 8 9 10 dist_cols=6 dist_rows=len (test_df.columns) plt.figure(figsize=(4 *dist_cols,4 *dist_rows)) i=1 for col in train_df.columns: ax=plt.subplot(dist_rows,dist_cols,i) ax=train_df[col].hist(bins=30 ) plt.xlabel(col) i+=1 plt.show()
散点图:
1 2 3 4 5 6 7 8 9 10 11 dist_cols=6 dist_rows=len (test_df.columns) plt.figure(figsize=(4 *dist_cols,4 *dist_rows)) i=1 for col in test_df.columns: ax=plt.subplot(dist_rows,dist_cols,i) ax=plt.scatter(train_df[col],train_df['orders_3h_15h' ]) plt.xlabel(col) plt.ylabel('orders_3h_15h' ) i+=1 plt.show()
查看训练集标签分布情况
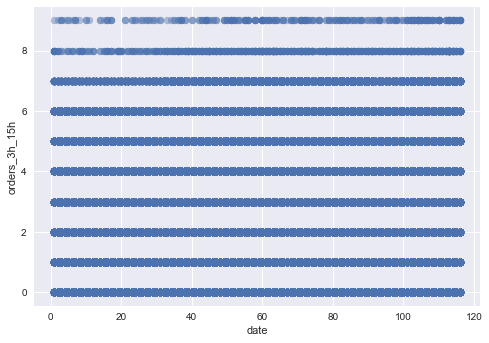
散点图:
1 2 3 4 plt.scatter(train_df['date' ],train_df['orders_3h_15h' ],alpha=0.4 ) plt.xlabel('date' ) plt.ylabel('orders_3h_15h' ) plt.show()
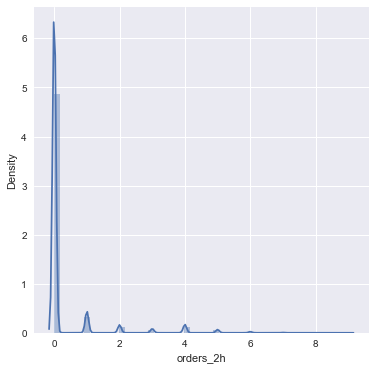
直方图:
1 2 fig=plt.figure(figsize=(6 ,6 )) sns.distplot(train_df['orders_2h' ])
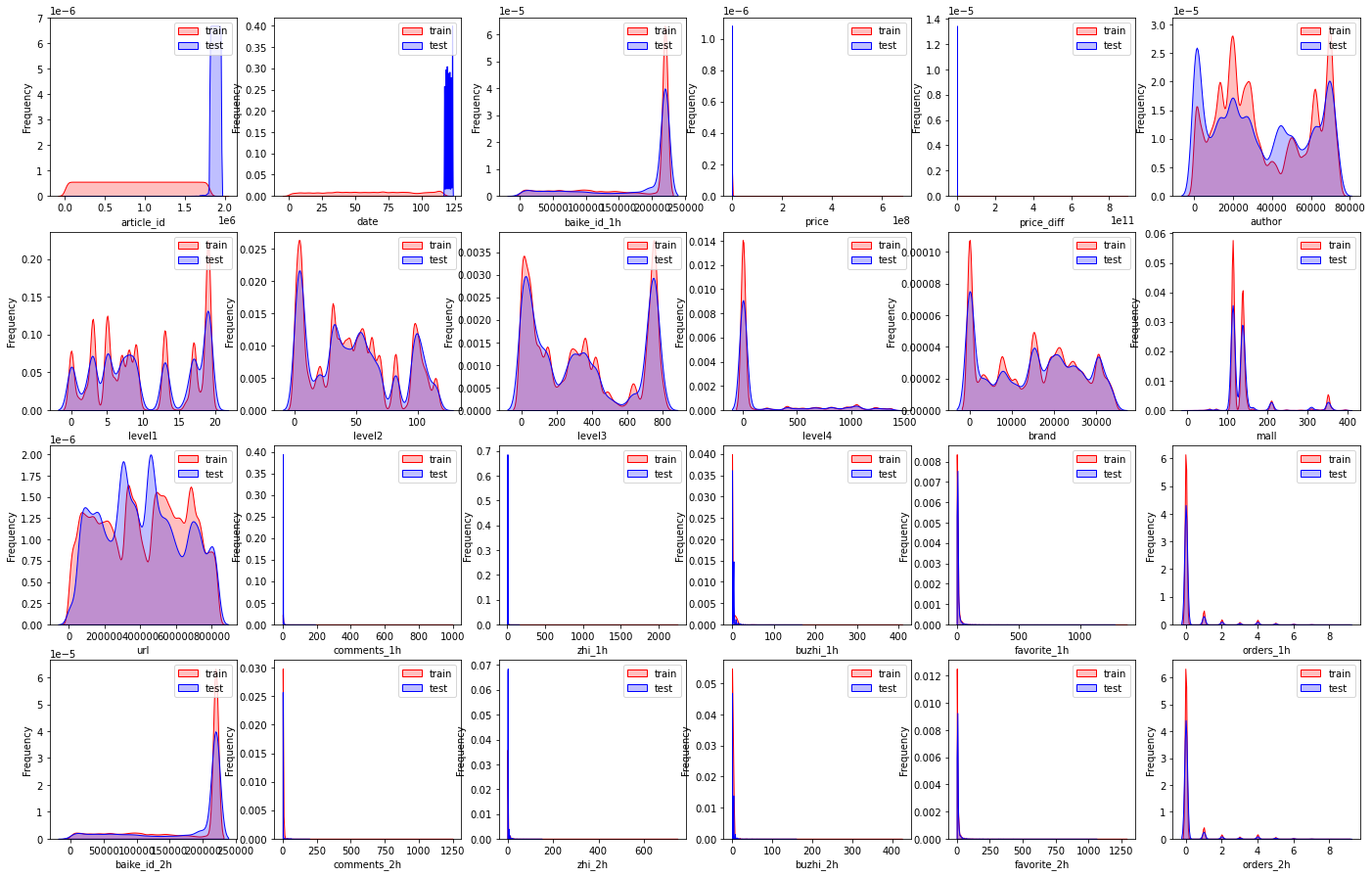
查看训练集和测试集的数据分布情况
1 2 3 4 5 6 7 8 9 10 11 12 13 dist_cols=6 dist_rows=len (test_df.columns) plt.figure(figsize=(4 *dist_cols,4 *dist_rows)) i=1 for col in test_df.columns: ax=plt.subplot(dist_rows,dist_cols,i) ax=sns.kdeplot(train_df[col],color='Red' ,shade=True ) ax=sns.kdeplot(test_df[col],color='Blue' ,shade=True ) ax.set_xlabel(col) ax.set_ylabel('Frequency' ) ax=ax.legend(['train' ,'test' ]) i+=1 plt.show()
建模预测初始方案:原始数据+LightGBM 这里选用树模型进行数据建模,采用的框架是LightGBM:
准备特征和标签:
1 2 3 x_train = train.drop(['article_id' ,'orders_3h_15h' ],axis=1 ) x_test = test.drop(['article_id' ],axis=1 ) y_train = train['orders_3h_15h' ]
定义训练函数:
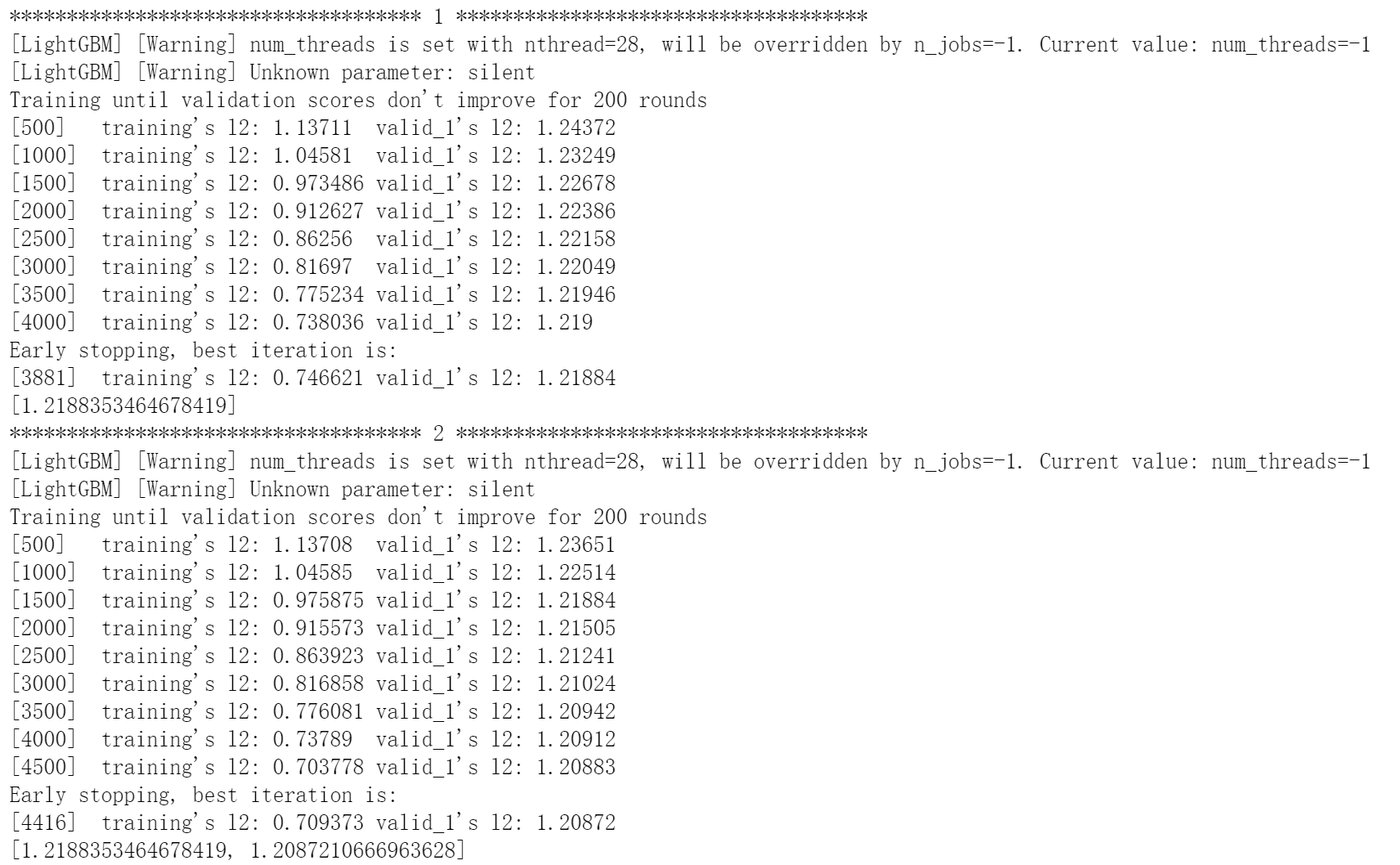
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 def cv_model (clf, train_x, train_y, test_x, clf_name='lgb' ): folds = 5 seed = 2021 kf = KFold(n_splits=folds, shuffle=True , random_state=seed) train = np.zeros(train_x.shape[0 ]) test = np.zeros(test_x.shape[0 ]) cv_scores = [] for i, (train_index, valid_index) in enumerate (kf.split(train_x, train_y)): print ('************************************ {} ************************************' .format (str (i+1 ))) trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index] train_matrix = clf.Dataset(trn_x, label=trn_y) valid_matrix = clf.Dataset(val_x, label=val_y) params = { 'boosting_type' : 'gbdt' , 'objective' : 'regression' , 'metric' : 'mse' , 'min_child_weight' : 5 , 'num_leaves' : 2 ** 7 , 'lambda_l2' : 10 , 'feature_fraction' : 0.9 , 'bagging_fraction' : 0.9 , 'bagging_freq' : 4 , 'learning_rate' : 0.1 , 'seed' : 2021 , 'nthread' : 28 , 'n_jobs' :-1 , 'silent' : True , 'verbose' : -1 , } model = clf.train(params, train_matrix, 5000 , valid_sets=[train_matrix, valid_matrix], verbose_eval=500 ,early_stopping_rounds=200 ) val_pred = model.predict(val_x, num_iteration=model.best_iteration) test_pred = model.predict(test_x, num_iteration=model.best_iteration) train[valid_index] = val_pred test += test_pred / kf.n_splits cv_scores.append(mean_squared_error(val_y, val_pred)) print (cv_scores) print ("%s_scotrainre_list:" % clf_name, cv_scores) print ("%s_score_mean:" % clf_name, np.mean(cv_scores)) print ("%s_score_std:" % clf_name, np.std(cv_scores)) return train, test
开始训练:
1 lgb_train, lgb_test = cv_model(lgb, x_train, y_train, x_test)
漫长的等待过后,训练完成了。
生成提交结果:
1 2 3 4 sample_submit=pd.DataFrame() sample_submit['article_id' ]=test['article_id' ] sample_submit['orders_3h_15h' ] = lgb_test sample_submit.to_csv('sub.csv' , index=False )
将生成的sub.csv提交到比赛平台,MSE得分:1.176
建模预测改进方案:特征工程+LightGBM 这里仅以训练集上的特征工程为例进行说明,对于测试集施加同样的操作即可。
频数特征
统计author,brand和mall这三个特征中的所有取值的出现次数,将出现次数作为新的特征:
1 2 3 4 5 6 7 8 temp=train['author' ].value_counts().to_dict() train['author_cnt' ]=train['author' ].map (temp) temp=train['brand' ].value_counts().to_dict() train['brand_cnt' ]=train['brand' ].map (temp) temp=train['mall' ].value_counts().to_dict() train['mall_cnt' ]=train['mall' ].map (temp)
聚合特征
emm,还是举个栗子吧,比如对于特征author,统计量为平均数,其它特征为level1;那么可以按照不同的作者进行分组,每一个小组内的特征取值都是属于同一个作者的;对于每一个小组内的特征取值,计算这些特征取值对应的level特征取值的平均数,最后返回一个和原数据列长度一样的新的列,这就是刚刚生成的特征,写成代码如下:
1 train.groupby('author')['level1'].transform(lambda x: x.mean())
概括一下这句代码的意思:按照不同作者对数据集进行分组,然后对每组的level1取值求平均值,返回一个和原列长度一样的新的特征列。
我选择的统计量如下:
1 count,mean,medium,var,std,max,min
分别对author,mall,brand进行分组,求每组中的level1,level2,level3,level4,orders_1h,orders_2h对应的以上统计量的值,就得到了新的特征:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 train['gp_author_level1_cnt' ]=train.groupby('author' )['level1' ].transform(lambda x: x.count()) train['gp_author_level2_cnt' ]=train.groupby('author' )['level2' ].transform(lambda x: x.count()) train['gp_author_level3_cnt' ]=train.groupby('author' )['level3' ].transform(lambda x: x.count()) train['gp_author_level4_cnt' ]=train.groupby('author' )['level4' ].transform(lambda x: x.count()) train['gp_mall_level1_cnt' ]=train.groupby('mall' )['level1' ].transform(lambda x: x.count()) train['gp_mall_level2_cnt' ]=train.groupby('mall' )['level2' ].transform(lambda x: x.count()) train['gp_mall_level3_cnt' ]=train.groupby('mall' )['level3' ].transform(lambda x: x.count()) train['gp_mall_level4_cnt' ]=train.groupby('mall' )['level4' ].transform(lambda x: x.count()) train['gp_brand_level1_cnt' ]=train.groupby('brand' )['level1' ].transform(lambda x: x.count()) train['gp_brand_level2_cnt' ]=train.groupby('brand' )['level2' ].transform(lambda x: x.count()) train['gp_brand_level3_cnt' ]=train.groupby('brand' )['level3' ].transform(lambda x: x.count()) train['gp_brand_level4_cnt' ]=train.groupby('brand' )['level4' ].transform(lambda x: x.count()) train['gp_author_level1_mean' ]=train.groupby('author' )['level1' ].transform(lambda x: x.mean()) train['gp_author_level2_mean' ]=train.groupby('author' )['level2' ].transform(lambda x: x.mean()) train['gp_author_level3_mean' ]=train.groupby('author' )['level3' ].transform(lambda x: x.mean()) train['gp_author_level4_mean' ]=train.groupby('author' )['level4' ].transform(lambda x: x.mean()) train['gp_mall_level1_mean' ]=train.groupby('mall' )['level1' ].transform(lambda x: x.mean()) train['gp_mall_level2_mean' ]=train.groupby('mall' )['level2' ].transform(lambda x: x.mean()) train['gp_mall_level3_mean' ]=train.groupby('mall' )['level3' ].transform(lambda x: x.mean()) train['gp_mall_level4_mean' ]=train.groupby('mall' )['level4' ].transform(lambda x: x.mean()) train['gp_brand_level1_mean' ]=train.groupby('brand' )['level1' ].transform(lambda x: x.mean()) train['gp_brand_level2_mean' ]=train.groupby('brand' )['level2' ].transform(lambda x: x.mean()) train['gp_brand_level3_mean' ]=train.groupby('brand' )['level3' ].transform(lambda x: x.mean()) train['gp_brand_level4_mean' ]=train.groupby('brand' )['level4' ].transform(lambda x: x.mean()) train['gp_author_level1_median' ]=train.groupby('author' )['level1' ].transform(lambda x: x.median()) train['gp_author_level2_median' ]=train.groupby('author' )['level2' ].transform(lambda x: x.median()) train['gp_author_level3_median' ]=train.groupby('author' )['level3' ].transform(lambda x: x.median()) train['gp_author_level4_median' ]=train.groupby('author' )['level4' ].transform(lambda x: x.median()) train['gp_mall_level1_median' ]=train.groupby('mall' )['level1' ].transform(lambda x: x.median()) train['gp_mall_level2_median' ]=train.groupby('mall' )['level2' ].transform(lambda x: x.median()) train['gp_mall_level3_median' ]=train.groupby('mall' )['level3' ].transform(lambda x: x.median()) train['gp_mall_level4_median' ]=train.groupby('mall' )['level4' ].transform(lambda x: x.median()) train['gp_brand_level1_median' ]=train.groupby('brand' )['level1' ].transform(lambda x: x.median()) train['gp_brand_level2_median' ]=train.groupby('brand' )['level2' ].transform(lambda x: x.median()) train['gp_brand_level3_median' ]=train.groupby('brand' )['level3' ].transform(lambda x: x.median()) train['gp_brand_level4_median' ]=train.groupby('brand' )['level4' ].transform(lambda x: x.median()) train['gp_author_level1_var' ]=train.groupby('author' )['level1' ].transform(lambda x: x.var()) train['gp_author_level2_var' ]=train.groupby('author' )['level2' ].transform(lambda x: x.var()) train['gp_author_level3_var' ]=train.groupby('author' )['level3' ].transform(lambda x: x.var()) train['gp_author_level4_var' ]=train.groupby('author' )['level4' ].transform(lambda x: x.var()) train['gp_mall_level1_var' ]=train.groupby('mall' )['level1' ].transform(lambda x: x.var()) train['gp_mall_level2_var' ]=train.groupby('mall' )['level2' ].transform(lambda x: x.var()) train['gp_mall_level3_var' ]=train.groupby('mall' )['level3' ].transform(lambda x: x.var()) train['gp_mall_level4_var' ]=train.groupby('mall' )['level4' ].transform(lambda x: x.var()) train['gp_brand_level1_var' ]=train.groupby('brand' )['level1' ].transform(lambda x: x.var()) train['gp_brand_level2_var' ]=train.groupby('brand' )['level2' ].transform(lambda x: x.var()) train['gp_brand_level3_var' ]=train.groupby('brand' )['level3' ].transform(lambda x: x.var()) train['gp_brand_level4_var' ]=train.groupby('brand' )['level4' ].transform(lambda x: x.var()) train['gp_author_level1_std' ]=train.groupby('author' )['level1' ].transform(lambda x: x.std()) train['gp_author_level2_std' ]=train.groupby('author' )['level2' ].transform(lambda x: x.std()) train['gp_author_level3_std' ]=train.groupby('author' )['level3' ].transform(lambda x: x.std()) train['gp_author_level4_std' ]=train.groupby('author' )['level4' ].transform(lambda x: x.std()) train['gp_mall_level1_std' ]=train.groupby('mall' )['level1' ].transform(lambda x: x.std()) train['gp_mall_level2_std' ]=train.groupby('mall' )['level2' ].transform(lambda x: x.std()) train['gp_mall_level3_std' ]=train.groupby('mall' )['level3' ].transform(lambda x: x.std()) train['gp_mall_level4_std' ]=train.groupby('mall' )['level4' ].transform(lambda x: x.std()) train['gp_brand_level1_std' ]=train.groupby('brand' )['level1' ].transform(lambda x: x.std()) train['gp_brand_level2_std' ]=train.groupby('brand' )['level2' ].transform(lambda x: x.std()) train['gp_brand_level3_std' ]=train.groupby('brand' )['level3' ].transform(lambda x: x.std()) train['gp_brand_level4_std' ]=train.groupby('brand' )['level4' ].transform(lambda x: x.std()) train['gp_author_level1_max' ]=train.groupby('author' )['level1' ].transform(lambda x: x.max ()) train['gp_author_level2_max' ]=train.groupby('author' )['level2' ].transform(lambda x: x.max ()) train['gp_author_level3_max' ]=train.groupby('author' )['level3' ].transform(lambda x: x.max ()) train['gp_author_level4_max' ]=train.groupby('author' )['level4' ].transform(lambda x: x.max ()) train['gp_mall_level1_max' ]=train.groupby('mall' )['level1' ].transform(lambda x: x.max ()) train['gp_mall_level2_max' ]=train.groupby('mall' )['level2' ].transform(lambda x: x.max ()) train['gp_mall_level3_max' ]=train.groupby('mall' )['level3' ].transform(lambda x: x.max ()) train['gp_mall_level4_max' ]=train.groupby('mall' )['level4' ].transform(lambda x: x.max ()) train['gp_brand_level1_max' ]=train.groupby('brand' )['level1' ].transform(lambda x: x.max ()) train['gp_brand_level2_max' ]=train.groupby('brand' )['level2' ].transform(lambda x: x.max ()) train['gp_brand_level3_max' ]=train.groupby('brand' )['level3' ].transform(lambda x: x.max ()) train['gp_brand_level4_max' ]=train.groupby('brand' )['level4' ].transform(lambda x: x.max ()) train['gp_author_level1_min' ]=train.groupby('author' )['level1' ].transform(lambda x: x.min ()) train['gp_author_level2_min' ]=train.groupby('author' )['level2' ].transform(lambda x: x.min ()) train['gp_author_level3_min' ]=train.groupby('author' )['level3' ].transform(lambda x: x.min ()) train['gp_author_level4_min' ]=train.groupby('author' )['level4' ].transform(lambda x: x.min ()) train['gp_mall_level1_min' ]=train.groupby('mall' )['level1' ].transform(lambda x: x.min ()) train['gp_mall_level2_min' ]=train.groupby('mall' )['level2' ].transform(lambda x: x.min ()) train['gp_mall_level3_min' ]=train.groupby('mall' )['level3' ].transform(lambda x: x.min ()) train['gp_mall_level4_min' ]=train.groupby('mall' )['level4' ].transform(lambda x: x.min ()) train['gp_brand_level1_min' ]=train.groupby('brand' )['level1' ].transform(lambda x: x.min ()) train['gp_brand_level2_min' ]=train.groupby('brand' )['level2' ].transform(lambda x: x.min ()) train['gp_brand_level3_min' ]=train.groupby('brand' )['level3' ].transform(lambda x: x.min ()) train['gp_brand_level4_min' ]=train.groupby('brand' )['level4' ].transform(lambda x: x.min ())
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 train['gp_author_orders_1h_cnt' ]=train.groupby('author' )['orders_1h' ].transform(lambda x: x.count()) train['gp_author_orders_2h_cnt' ]=train.groupby('author' )['orders_2h' ].transform(lambda x: x.count()) train['gp_mall_orders_1h_cnt' ]=train.groupby('mall' )['orders_1h' ].transform(lambda x: x.count()) train['gp_mall_orders_2h_cnt' ]=train.groupby('mall' )['orders_2h' ].transform(lambda x: x.count()) train['gp_brand_orders_1h_cnt' ]=train.groupby('brand' )['orders_1h' ].transform(lambda x: x.count()) train['gp_brand_orders_2h_cnt' ]=train.groupby('brand' )['orders_2h' ].transform(lambda x: x.count()) train['gp_author_orders_1h_mean' ]=train.groupby('author' )['orders_1h' ].transform(lambda x: x.mean()) train['gp_author_orders_2h_mean' ]=train.groupby('author' )['orders_2h' ].transform(lambda x: x.mean()) train['gp_mall_orders_1h_mean' ]=train.groupby('mall' )['orders_1h' ].transform(lambda x: x.mean()) train['gp_mall_orders_2h_mean' ]=train.groupby('mall' )['orders_2h' ].transform(lambda x: x.mean()) train['gp_brand_orders_1h_mean' ]=train.groupby('brand' )['orders_1h' ].transform(lambda x: x.mean()) train['gp_brand_orders_2h_mean' ]=train.groupby('brand' )['orders_2h' ].transform(lambda x: x.mean()) train['gp_author_orders_1h_median' ]=train.groupby('author' )['orders_1h' ].transform(lambda x: x.median()) train['gp_author_orders_2h_median' ]=train.groupby('author' )['orders_2h' ].transform(lambda x: x.median()) train['gp_mall_orders_1h_median' ]=train.groupby('mall' )['orders_1h' ].transform(lambda x: x.median()) train['gp_mall_orders_2h_median' ]=train.groupby('mall' )['orders_2h' ].transform(lambda x: x.median()) train['gp_brand_orders_1h_median' ]=train.groupby('brand' )['orders_1h' ].transform(lambda x: x.median()) train['gp_brand_orders_2h_median' ]=train.groupby('brand' )['orders_2h' ].transform(lambda x: x.median()) train['gp_author_orders_1h_var' ]=train.groupby('author' )['orders_1h' ].transform(lambda x: x.var()) train['gp_author_orders_2h_var' ]=train.groupby('author' )['orders_2h' ].transform(lambda x: x.var()) train['gp_mall_orders_1h_var' ]=train.groupby('mall' )['orders_1h' ].transform(lambda x: x.var()) train['gp_mall_orders_2h_var' ]=train.groupby('mall' )['orders_2h' ].transform(lambda x: x.var()) train['gp_brand_orders_1h_var' ]=train.groupby('brand' )['orders_1h' ].transform(lambda x: x.var()) train['gp_brand_orders_2h_var' ]=train.groupby('brand' )['orders_2h' ].transform(lambda x: x.var()) train['gp_author_orders_1h_std' ]=train.groupby('author' )['orders_1h' ].transform(lambda x: x.std()) train['gp_author_orders_2h_std' ]=train.groupby('author' )['orders_2h' ].transform(lambda x: x.std()) train['gp_mall_orders_1h_std' ]=train.groupby('mall' )['orders_1h' ].transform(lambda x: x.std()) train['gp_mall_orders_2h_std' ]=train.groupby('mall' )['orders_2h' ].transform(lambda x: x.std()) train['gp_brand_orders_1h_std' ]=train.groupby('brand' )['orders_1h' ].transform(lambda x: x.std()) train['gp_brand_orders_2h_std' ]=train.groupby('brand' )['orders_2h' ].transform(lambda x: x.std()) train['gp_author_orders_1h_max' ]=train.groupby('author' )['orders_1h' ].transform(lambda x: x.max ()) train['gp_author_orders_2h_max' ]=train.groupby('author' )['orders_2h' ].transform(lambda x: x.max ()) train['gp_mall_orders_1h_max' ]=train.groupby('mall' )['orders_1h' ].transform(lambda x: x.max ()) train['gp_mall_orders_2h_max' ]=train.groupby('mall' )['orders_2h' ].transform(lambda x: x.max ()) train['gp_brand_orders_1h_max' ]=train.groupby('brand' )['orders_1h' ].transform(lambda x: x.max ()) train['gp_brand_orders_2h_max' ]=train.groupby('brand' )['orders_2h' ].transform(lambda x: x.max ()) train['gp_author_orders_1h_min' ]=train.groupby('author' )['orders_1h' ].transform(lambda x: x.min ()) train['gp_author_orders_2h_min' ]=train.groupby('author' )['orders_2h' ].transform(lambda x: x.min ()) train['gp_mall_orders_1h_min' ]=train.groupby('mall' )['orders_1h' ].transform(lambda x: x.min ()) train['gp_mall_orders_2h_min' ]=train.groupby('mall' )['orders_2h' ].transform(lambda x: x.min ()) train['gp_brand_orders_1h_min' ]=train.groupby('brand' )['orders_1h' ].transform(lambda x: x.min ()) train['gp_brand_orders_2h_min' ]=train.groupby('brand' )['orders_2h' ].transform(lambda x: x.min ())
合成特征
比如计算文章前1个小时对应的商品id与文章前2个小时对应的商品id的交并比:
1 len (set (train['baike_id_1h' ] & train['baike_id_2h' ]))/len (set (train['baike_id_1h' ] | train['baike_id_2h' ]))
再比如计算文章前2个小时值数与文章前1个小时值数的比值(为了防止分母为0,给分母加1):
1 train['buzhi_2h' ]/(1 +train['buzhi_1h' ])
等等等等,这里不再一一说明,直接上代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 train['baike_iou' ]=len (set (train['baike_id_1h' ] & train['baike_id_2h' ]))/len (set (train['baike_id_1h' ] | train['baike_id_2h' ])) train['price_this' ]=train['price' ]+train['price_diff' ] train['price_ratio' ]=train['price_diff' ]/train['price' ] train['favorite_diff' ]=train['favorite_2h' ]-train['favorite_1h' ] train['zhi_diff' ]=train['zhi_2h' ]-train['zhi_1h' ] train['buzhi_diff' ]=train['buzhi_2h' ]-train['buzhi_1h' ] train['orders_diff' ]=train['orders_2h' ]-train['orders_1h' ] train['comments_diff' ]=train['comments_2h' ]-train['comments_1h' ] train['price_last' ]=train['price' ]-train['price_diff' ] train['price_increase_ratio' ]=(train['price_last' ]+train['price_diff' ])/train['price_last' ] train['favorite_increase_ratio' ]=train['favorite_2h' ]/(1 +train['favorite_1h' ]) train['zhi_increase_ratio' ]=train['zhi_2h' ]/(1 +train['zhi_1h' ]) train['buzhi_increase_ratio' ]=train['buzhi_2h' ]/(1 +train['buzhi_1h' ]) train['orders_increase_ratio' ]=train['orders_2h' ]/(1 +train['orders_1h' ]) train['comments_increase_ratio' ]=train['comments_2h' ]/(1 +train['comments_1h' ])
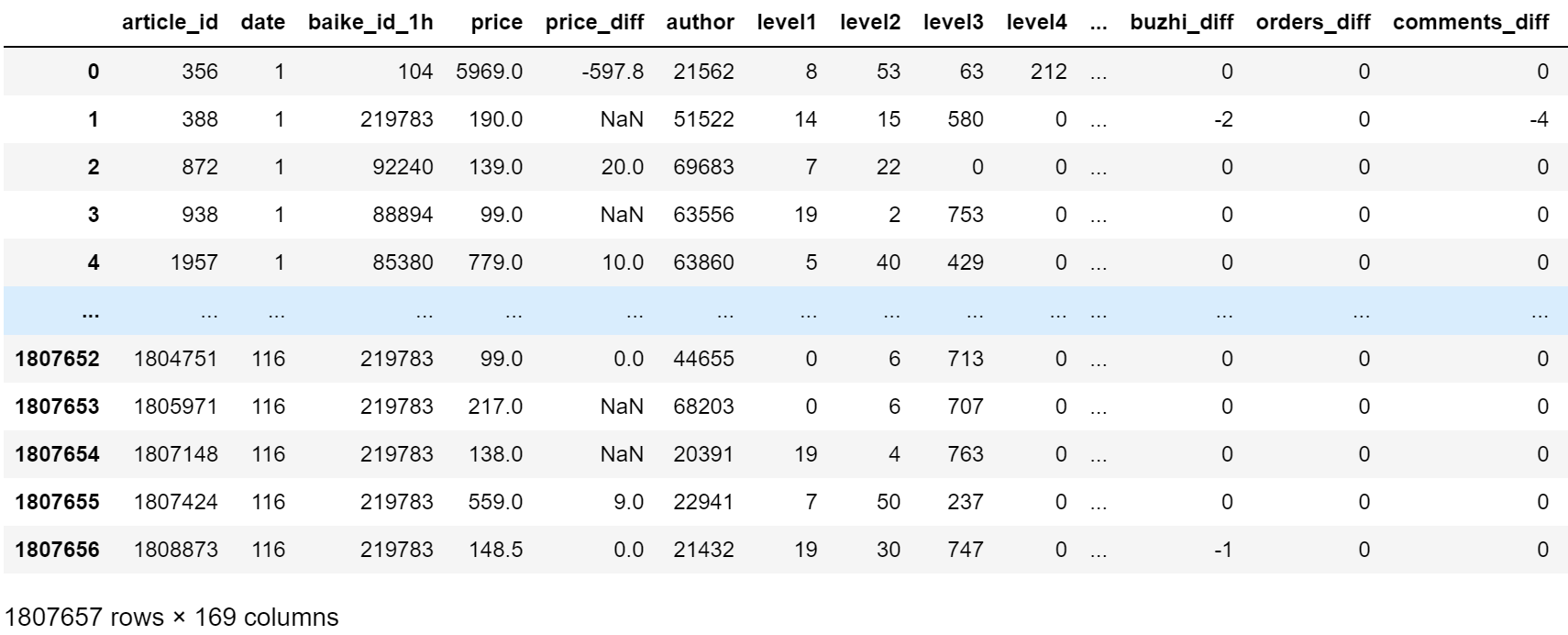
经过以上一顿操作,特征数由最开始的24个变成了168个:
将这些新的特征再次送入LightGBM,训练,生成预测结果,提交结果,MSE得分:1.157
相比于之前的1.176确实有提升。
后来,我又调了些参数,主要是防止模型过拟合:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 def cv_model (clf, train_x, train_y, test_x, clf_name='lgb' ): folds = 5 seed = 2021 kf = KFold(n_splits=folds, shuffle=True , random_state=seed) train = np.zeros(train_x.shape[0 ]) test = np.zeros(test_x.shape[0 ]) cv_scores = [] for i, (train_index, valid_index) in enumerate (kf.split(train_x, train_y)): print ('************************************ {} ************************************' .format (str (i+1 ))) trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index] train_matrix = clf.Dataset(trn_x, label=trn_y) valid_matrix = clf.Dataset(val_x, label=val_y) params = { 'boosting_type' : 'gbdt' , 'objective' : 'regression' , 'metric' : 'mse' , 'min_child_weight' : 5 , 'max_depth' : 10 , 'num_leaves' : 2 ** 4 , 'lambda_l2' : 10 , 'feature_fraction' : 0.9 , 'bagging_fraction' : 0.9 , 'bagging_freq' : 4 , 'learning_rate' : 0.1 , 'seed' : 2021 , 'nthread' : 28 , 'n_jobs' :-1 , 'silent' : True , 'verbose' : -1 , } model = clf.train(params, train_matrix, 5000 , valid_sets=[train_matrix, valid_matrix], verbose_eval=500 ,early_stopping_rounds=200 ) val_pred = model.predict(val_x, num_iteration=model.best_iteration) test_pred = model.predict(test_x, num_iteration=model.best_iteration) train[valid_index] = val_pred test += test_pred / kf.n_splits cv_scores.append(mean_squared_error(val_y, val_pred)) print (cv_scores) print ("%s_scotrainre_list:" % clf_name, cv_scores) print ("%s_score_mean:" % clf_name, np.mean(cv_scores)) print ("%s_score_std:" % clf_name, np.std(cv_scores)) return train, test
使用上述参数再次训练,提交结果的MSE得分:1.1560
可能的改进方案 虽然以上操作确实可以提升模型的效果,但相比于大佬们的成绩来说仅算是个baseline。这里提供几个可能的改进方向:
继续调参
更精细的特征工程
尝试其它机器学习模型
尝试深度学习模型
模型融合
在之后,我们也会解读比赛前几名大佬的开源方案,欢迎持续关注~