

回归树
开篇在之前的决策树讲解(传送门)中,我们使用ID3算法生成了一棵决策树,并且在文章最后指出除了ID3算法,常用的决策树生成算法还有C4.5。
但是,无论是基于信息增益的ID3算法,还是基于信息增益比的C4.5算法,它们都只能处理分类问题,而对于回归问题就束手无策了。
现在,我们要介绍一种既可用于分类任务又可用于回归任务的决策树的生成算法:CART算法。
CART的全称是 classification and regression tree,译为分类与回归树,该算法由两步组成:(1)决策树生成;(2)决策树剪枝。
本文重点关心如何用决策树做回归任务,因此本文的主题是讲解回归树的生成原理及其Python实现。下面正文开始。
回归树的生成对于使用ID3算法或者C4.5算法生成的决策树,这棵树可能是多岔的,因为某个被选定用于划分数据集的特征的不同取值可能多于两个。而这里基于CART算法的决策树,无论是回归树还是分类树,它们都是二叉树。
以回归树为例,为什么是二叉树呢?这还得从回归树的生成原理讲起。
对于给定的训练集$(X,Y)$,其中$Y$是连续型变量,首先*按照某种方法选择某一个特征(这里记 ...
AdaBoost
开篇AdaBoost是一种提升(boosting)方法。
你可能听过“众人拾柴火焰高”这句话,提升方法的思想与这句话的思想颇有相似之处。
一个人拾到的柴火,只能维持小的火苗;但一群人一起拾柴,供给同一火堆,那么这个火堆终将燃起熊熊大火。
对于给定的训练集,单个分类器的分类能力可能并不算好;但如果同时训练一堆分类器,让分类器们一起做判断,那么分类结果将会比任何一个单独的分类器做分类都要好。
上面的单个分类器被称为“弱分类器”,若干个“弱分类器”联合起来,就得到了“强分类器”。
AdaBoost作为最具代表性的提升方法,自然也蕴含着这种集体智慧的思想。至于其具体细节,且往下看。
AdaBoost 算法AdaBoost为训练集中每个样本设置一个可调整的权值,并且在每一轮训练结束后将被误分类的样本的权值加大,将被正确分类的样本的权值减小。这样被误分类的样本在下一轮分类时会更加受到关注。
假设经过了$M$轮训练,则会得到$M$个弱分类器。将这$M$个弱分类器通过加权求和(弱分类器分类能力相对越强,权值就越大)的方式联结起来,便得到了一个强分类器。
以上是AdBoost核心思想的文字描述,现在用数 ...

朴素贝叶斯
开篇正如其名,”朴素贝叶斯”原理”朴素”,实现简单,是一种常用的机器学习算法。
为何“朴素”?如何“学习”?如何分类?别急,咱们慢慢道来~
概率统计回忆录朴素贝叶斯也是贝叶斯方法的一种,提起贝叶斯,学过概率统计的你一定听说过条件概率公式,全概率公式和贝叶斯公式吧,忘记了也没关系,我们先来快速过一遍。
条件概率公式:
$$P(A|B)=\frac{P(A,B)}{P(B)}$$
全概率公式:
$$P(B)=\sum_{i=1}^{n}P(A_i)P(B|A_i)$$
贝叶斯公式:
$$P(A|B)=\frac{P(A,B)}{P(B)}=\frac{P(B|A)P(A)}{ \sum_{i=1}^{n}P(A_i)P(B|A_i)}$$
可以发现,贝叶斯公式其实就是由条件概率公式和全概率公式推导的,贝叶斯公式的分母是一个全概率公式,分子是一个条件概率公式。
后续的推导将会用到上面的公式。
朴素贝叶斯的训练(学习)方法朴素贝叶斯在使用训练数据进行“学习”时,其实是在学习数据的生成机制,具体点,是在学习特征$X$与标签$Y$的联合概 ...

决策树
开篇决策树,可以看做一个if-else规则的集合,比如下图就是一棵决策树:
其中,圆圈代表特征,矩形代表最终的类别,圆圈和矩形都可以称为树的节点,决策树正是由这样一个个节点组成的。
本文的主要内容是从零开始构建一棵决策树,中间过程会涉及诸如熵,信息增益以及决策树等概念。
按照老规矩,先上栗子。
信贷决策问题这里有一份数据集,其中每个ID代表一个人,类别列代表是否同意这个人的贷款申请,中间列(年龄,有工作,有自己的房子,信贷情况)是4个特征,现在要求你利用这四个特征及类别标签,构建一棵决策树来决定是否同意贷款申请人的贷款申请。
ID
年龄
有工作
有自己的房子
信贷情况
类别
1
青年
否
否
一般
否
2
青年
否
否
好
否
3
青年
是
否
好
是
4
青年
是
是
一般
是
5
青年
否
否
一般
否
6
中年
否
否
一般
否
7
中年
否
否
好
否
8
中年
是
是
好
是
9
中年
否
是
非常好
是
10
中年
否
是
非常好
是
11
老年
否
是
非常好
是
12
老年
否
是
好
是
13
老年
是
否 ...

异常处理_Python基础连载(十五)
开篇本期介绍Python的异常处理方法。
为什么需要做异常处理看下面的函数:
12def div(a,b): return a/b
这个函数用于求解两数相除的结果
我们可以调用它:
12345678#求解1/2>>> div(1,2)0.5#求解3/4>>> div(3,4)0.75
程序貌似没问题
但是我们知道,除数是不能为0的,现在来尝试让除数为0:
1234567>>> div(1,0)Traceback (most recent call last): File "<pyshell#2>", line 1, in <module> div(1,0) File "C:/Users/fanxi/Desktop/swe.py", line 2, in div return a/bZeroDivisionError: division by zero
毫无疑问,程序报错了!
报错信息也很明显:ZeroDivisionError: divis ...

排序_不止于升降-Python基础连载(十四)
开篇本期将介绍排序方法,注意是方法而不是算法,因此更侧重方法的使用,而不对其内部细节的实现原理进行深究。
简单的列表(list)排序list自带有sort()方法可实现排序
默认是升序排列:
1234>>> lis=[1,3,2,5,4,8,6,9]>>> lis.sort()>>> lis[1, 2, 3, 4, 5, 6, 8, 9]
可通过传入reverse=True来实现降序:
1234>>> lis=[1,3,2,5,4,8,6,9]>>> lis.sort(reverse=True)>>> lis[9, 8, 6, 5, 4, 3, 2, 1]
你应该已经发现,上述的排序操作是直接在原列表中进行的。
除了上面的sort(),Python语言本身也有一种排序的函数,叫做sorted()
同样默认是升序排列:
1234>>> lis=[1,3,2,5,4,8,6,9]>>> sorted_lis=sorted(lis)>>& ...

Python将批量图片转pdf
最近在整理以前的书籍和资料,发现了一堆自己写的笔记:
摊开之后的画面是这样的:
丢了吧,太可惜,留着呢,又用不到,而且还占地方。思来想去,我决定将它们扫描做成电子档,永久储存在云端。
说干就干,先拿<操作系统笔记>开刀。我用手机摄像头充当扫描仪,开始了漫长的扫描,这真是个体力活。
许久,终于扫描完了,共134张图片。二话不说,在手机相册中选中扫描的图片,传送到手机wps,开始合成pdf…
然后就好了………………………………………………………吗?
事实是:wps最高只支持一次将50张图片合成pdf,而且还是在开会员的前提下才能操作。emm, 看来要另寻他法了。
一个新的想法是,把图片全部弄进word里,导出pdf就好了
这确实可行,但是每两张图片之间的间隔实在是太大了,有点丑
而且作为一个Python爱好者,一遇到问题,就习惯性的想着能不能用Python来解决
因为如果下次,你有1000份文档的图片需要转pdf,使用word的话,你需要手动创建1000个word文档,然后做1000次导入图片的操作,这可真让人手酸。
拥抱Python吧!
经过一番搜索,我发现了img2pdf这 ...

kd树
开篇在讲解k-近邻算法的时候,我们提供的思路是:对于新到来的样本,计算该样本与训练集中所有样本之间的距离,选取训练集中距离新样本最近的k个样本中大多数样本的类别作为新的样本的类别。
也就是说,每次都要计算新的样本与训练集中全部样本的距离。但是,在实际应用中,训练集的样本量和特征维度都是比较庞大的,这就导致该算法不得不在计算距离上花费大量的时间,那有没有什么方法可以在时间开销上对之前的k-近邻算法进行优化呢?
采用以空间来换时间的思想,就引出了今天的主角:kd树。
构造kd树kd树是一种二叉树,它可以将k维特征空间中的样本进行划分存储,以便实现快速搜索。
一头雾水?没关系,来看一个经典的构造kd树的例子。
现给定一个二维的训练集:T={(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}
要求构造一个平衡kd树
第一步,选取第0个维度作为被划分的坐标轴,并按照第0个维度从小到大排列全部样本,得到:
{(2,3),(4,7),(5,4),(7,2),(8,1),(9,6)}
第二步,找到第0个维度的中位数对应的样本。注意,这里的中位数与我们之前认知的中 ...
k-近邻算法
开篇k-近邻算法是比较简单的一种机器学习算法,其核心思想可以用一句话来概括:近朱者赤,近墨者黑。
在具体介绍该算法之前,先通过一个栗子对该算法做一个感性上的认识。
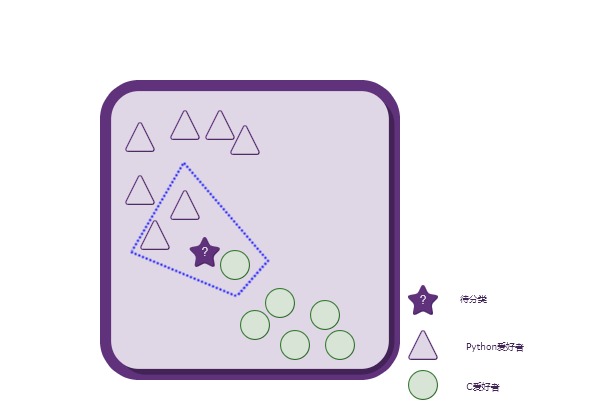
Python爱好者 or C爱好者 ?
上图中,每一个形状(三角形,圆形)都代表了一个人。总共有两种形状,说明这些人总共可以分为两类:Python爱好者、C爱好者。
三角形一共有7个,代表喜欢写Python的总共有7人;
圆形一共有6个,代表喜欢写C语言的总共有6人。
现在,突然来了一个不知道是喜欢写Python还是C语言(并且只可能属于其中之一)的人—–五角星,要求你来判定这个人所属的类别。
emm…
你可能会说,那看看图上距离这个人(五角星)最近的几个人所属类别就可以了啊!比如就看距离这个人最近的3个人:其中有两个人喜欢写Python,而只有一个人喜欢写C语言(如下图所示)
按照少数服从多数的原则,将这个新来的人(五角星)归类到三角形(Python爱好者)类别就搞定啦!
最终 ...

从模型演化的角度看待国家的发展
时代在发展,社会也在不断地前进。得益于中国特色社会主义,近些年来,我们的生活也发生了翻天覆地的变化,这不仅仅体现在我们的衣食住行,更体现在精神与文化层面。科技日益发达,大国之间的竞争的焦点也渐渐转移到科学技术上来,尤其是进入21世纪以后,深度学习技术的突飞猛进,人工智能技术迅速发展,并且随着算力的不断提升,以前不可能实现的实验,现在都可交由计算机来实现。依托其强大的运算能力和重复特性,如今的人工智能已经有了许多不错的落地成果。我们国家也在大力倡导发展大数据与人工智能,为促进新时代科技强国打下坚实的基础,这也正是我选择跨考进入计算机专业并准备在机器学习、人工智能方向深耕的原因之一。
中国特色社会主义结合了马克思主义与中国的实际国情,在先辈们前仆后继的不断摸索中,才有了今天来之不易的幸福生活,才给了发展高新科技的前提条件。生于20世纪与21世纪的交叉点的我们,更应该珍惜这来之不易的生活,同时也要根据自身条件,努力为社会主义的建设添砖加瓦,贡献自己的力量。于我而言,作为一名计算机专业并对机器学习技术非常热爱的研究生,更要努力学习相关知识。从小的说,是为了自己,往大了说,真心希望自己可以学有所 ...

