

WGAN
网络结构在基础GAN或DCGAN(本文)的基础上,使用推土机距离衡量真实样本分布与生成样本分布之间的距离,此时,即使两个分布没有重合部分(这经常发生,容易导致梯度突变),也能准确的衡量分布的差异。
从上图可以看出,WGAN的梯度永远不会为0,而普通GAN会出现梯度为0的情况。
根据
可以确定判别器和生成器的损失为:
其中,1-Lipscgitz是指$||f(x_1)-f(x_2)||\le1*||x_1-x_2||$
也就是导数要≤1
这一点,可以通过对权值进行clip的方式,使得权值固定在某个区间内,从而也使得导数固定在某一区间内(比如≤1)
下面的代码在DCGAN的基础上,修改了判别器和生成器的损失函数,并在每次权值更新后做了权值裁剪,其余未变。
导入相关函数12345import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layersimport matplotlib.pyplot as pltimport numpy as np
准备数据1(train_imag ...

LSGAN
网络结构在DCGAN(本文)或者普通GAN的基础上,将交叉熵损失改为均方误差损失,就得到了LSGAN
LSGAN是对之前两种GAN的优化,因为当生成器生成的数据分布$P_G$与数据的真实分布$P_{data}$不重叠时,JS散度永远都是log2,从而导致生成器难以更新,见下图
导入相关函数12345import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layersimport matplotlib.pyplot as pltimport numpy as np
准备数据1(train_images,_),(_,_)=tf.keras.datasets.mnist.load_data()
1train_images.shape
(60000, 28, 28)
1train_images.dtype
dtype('uint8')
1train_images=train_images.reshape(train_images.shape[ ...
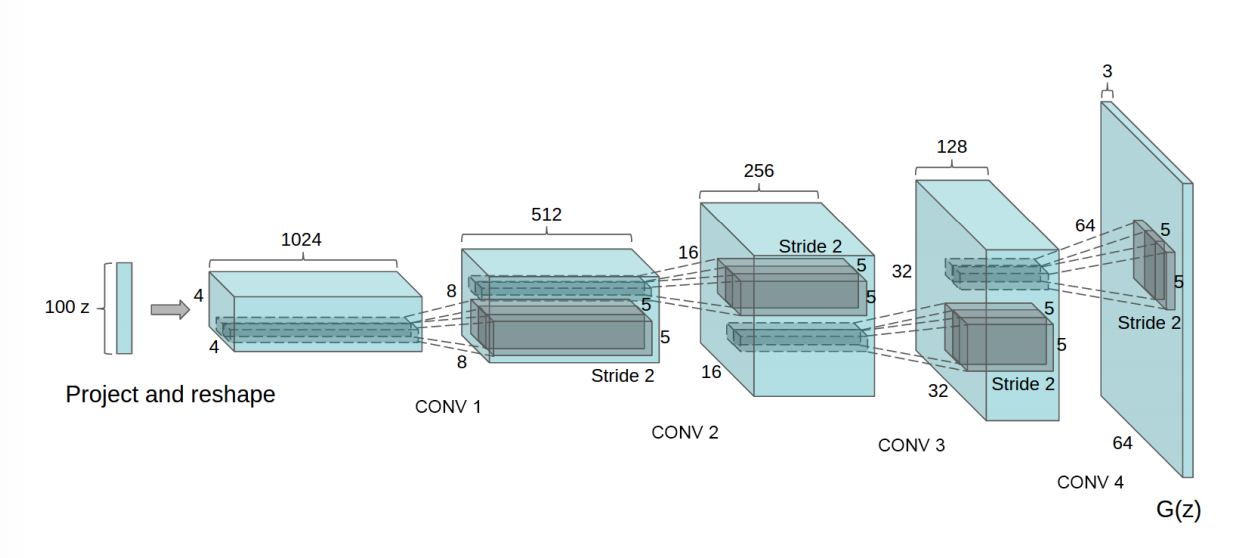
DCGAN
网络结构同普通GAN ,只是将生成器与判别器网络中的Dense层换为了卷积层与转置卷积层,故整体代码只需改动生成器和判别器的网络搭建函数即可。
导入相关函数12345import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layersimport matplotlib.pyplot as pltimport numpy as np
准备数据1(train_images,_),(_,_)=tf.keras.datasets.mnist.load_data()
1train_images.shape
(60000, 28, 28)
1train_images.dtype
dtype('uint8')
1train_images=train_images.reshape(train_images.shape[0],28,28,1).astype('float32')
1train_images.shape
(6000 ...
基础GAN
网络结构
导入相关函数12345import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layersimport matplotlib.pyplot as pltimport numpy as np
准备数据1(train_images,_),(_,_)=tf.keras.datasets.mnist.load_data()
1train_images.shape
(60000, 28, 28)
1train_images.dtype
dtype('uint8')
1train_images=train_images.reshape(train_images.shape[0],28,28,1).astype('float32')
1train_images.shape
(60000, 28, 28, 1)
1train_images.dtype
dtype('float32')
1 ...
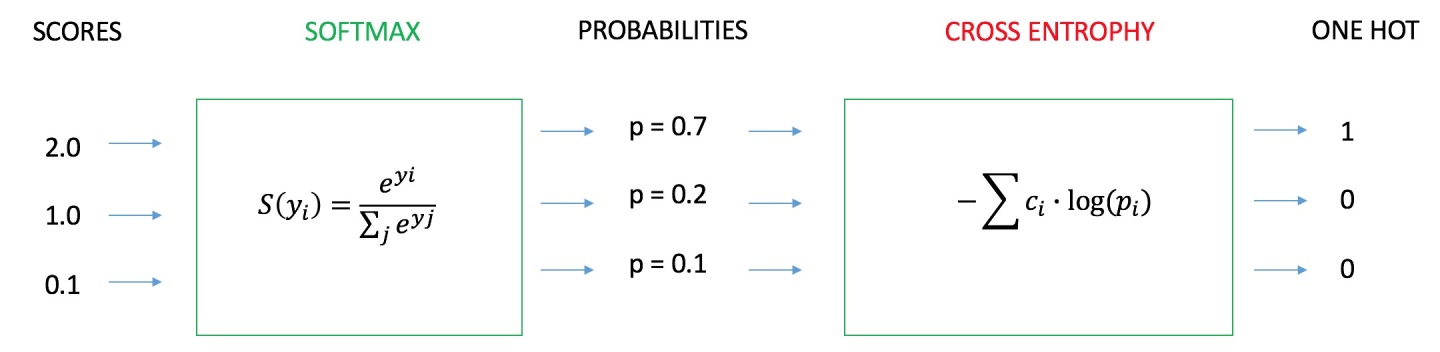
【常用于分类问题】交叉熵、相对熵
假设有离散型随机变量X的两个概率分布$p(x)$和$q(x)$,其中$p(x)$是数据的真实分布,$q(x)$是预测的数据分布。使用交叉熵或相对熵来度量$q(x)$逼近$p(x)$的效果,逼近程度越高,则两者的交叉熵或者相对熵就越小,因此可作为损失函数。
交叉熵$$H(p,q)=\sum_ip(x_i)log\frac1{q(x_i)}=-\sum_ip(x_i)log(q(x_i))$$
二分类对于二分类问题,真实标签一般用0和1来表示,假设真实的标签为$y_1,y_2,…,y_k$,预测得到的列向量为$yp_1,yp_2,…yp_k$
其中$y_i\in{0,1},i=1,2,…,k$
则交叉熵损失为$$H(y,yp)=-(y_1log(yp_1)+y_2log(yp_2)+…+y_klog(yp_k))$$
举个例子,假设共4个样本,其真实标签分别是$$ \begin{bmatrix} 1 &0&1&0 \end{bmatrix}$$(经sigmoid激活函数)预测输出得到$$ \begin{bmatrix} ...

幻听
转瞬即逝的美丽最适合在一遍又一遍的怀念里打磨出永恒的光彩
在远方的时候
又想你到泪流
这矫情的措辞结构
经历过的人会懂
那些不堪言的疼痛
也就是我自作自受
你没有装聋
你真没感动
一个人的时候
偷偷看你的微博
你转播的歌好耳熟
我们坐一起听过
当日嫌它的唱法做作
现在听起来竟然很生动
可能是时光让耳朵变得宽容
如今一个人听歌总是会觉得失落
幻听你在我的耳边轻轻诉说
夜色多温柔
你有多爱我
如今一个人听歌总是会觉得难过
爱已不在这里我却还没走脱
列表里的歌
随过往流动
一个人的时候
偷偷看你的微博
你每天做了些什么
我都了然于胸
当时嫌你的蠢话太多
现在回想起画面已泛旧
可能是孤独让情绪变得脆弱
如今一个人听歌总是会觉得失落
幻听你在我的耳边轻轻诉说
夜色多温柔
你有多爱我
如今一个人听歌总是会觉得难过
爱已不在这里我却还没走脱
列表里的歌
随过往流动
如今一个人听歌总是会觉得失落
幻听你在我的耳边轻轻诉说
夜色多温柔
你有多爱我
如今一个人听歌总是会觉得难过
爱已不在这里我却还没走脱
如果你回头
不要放下我

高阶函数,匿名函数-Python基础连载(十三)
开篇前面已经学习了函数以及函数的各种形式的参数。
本期要介绍的高阶函数也是函数的一种,只不过与普通的函数不同的是,高阶函数的参数可以是另外一个函数,高阶函数的返回值也可以是另外一个函数。
本期你将学习到Python的3个常用高阶函数:
map()、filter()和reduce()。
你完全可以把高阶函数看做是一个正常的函数(本来就是),只不过其参数和返回值可以是函数。这样学习起来可能会更加轻松。
mapmap用于对某一个可迭代对象中的每一个元素施加同一种操作。
map()有两个参数,第一个参数是一个函数,第二个参数是一个可迭代对象。
还是拿栗子来说明:
对于列表lis=[1,2,3],将列表中的每一个元素做平方操作,并将结果存入新的列表
如果采用普通的函数解答,你应该能写出如下的类似代码:
12345678910lis=[1,2,3]#求平方的函数def square(x): return x**2new=[]#遍历求平方for x in lis: temp=square(x) new.append(temp)print(new)
而若使用map函数,代码是这样子的 ...

函数,化繁为简-Python基础连载(十二)
开篇考虑这么一个问题:
求解1到4之和
到现在,你已经学习了分支循环以及六大数据类型,所以这题很简单啦,你应该能很轻松的写出下面的代码:
1234sum=0for i in range(1,5): sum+=iprint('1+2+3+4=',sum)
bingo!
那如果问题改为求解1到10之和呢?
也不难对吧,只需对range()稍作修改:
1234sum=0for i in range(1,11): sum+=iprint('1+2+...+10=',sum)
那如果问题改为求解1到100,1到1000之和呢?
同样是修改range()中的数字即可!
仔细思考一下,你会发现,上面的几个问题其实可以归纳为一个问题:求和
每个问题的解答代码其实都只是更改了range()中的一个数字
如果对于每一个问题,我们都去写一段上面的代码,那简直是灾难!因为会出现大量重复的代码。
所以,函数应运而生!
初识函数函数的结构如下:
其中的def是关键字,func是可自定义的函数名,x是函数的参数,可以有多个(这里的举的栗子只有一个),函数体内书写 ...

那些年
不知道那是梦境还是真实发生过,依稀记得18年的某个夏夜瞎溜达的时候到过这里,当时夜色浓重到干扰视线,我也只是远远地驻足观望,便迎着隐匿的月光转身而去了,脑海闪过的零星碎片,也被几里之外响彻黑夜的车笛声带去了遥不可测的夜空。
已经许多年没有特意走过这条路了,一些东西,也只有在紧闭双眼的时候才能看得见…
第一年…
“老师,我没有书!”
“我这里有两本,这个应该是你的”
第二年…
下午3点的天空,黑色浸染了时间之光,脱缰的风终于获得了自由,嘲笑着世间万物,教室里最后的光也被吞噬殆尽,两刻钟后,太阳露出了劫后余生般的微笑。
第三年…
“这种植物其实就在我们身边,现在你们去采集一些,注意不要跑远了”
第四年…
“去这么早做什么,再等会儿”
“走,玩去”
第五年…
“请用这些词写一篇作文,文体不限,字数不限”
第六年…
那年的夏天是经历过的最热的夏天,撕掉了好几本书,只为完成一个精美的工艺品,一个直到现在还保留着的美好亦或是虚幻
记得的永远会记得,记不得的也永远记不起了:
第一年的模型还不能正确区分语文与数学两字在写法上的不 ...

LSTM
可以把 lstm的memory看做一个neural
LSTM的解释图:
一个neural的工作过程
有点RNN的味道了
真正的LSTM

