
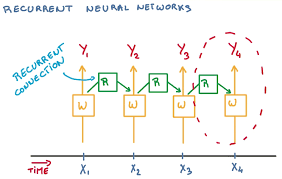
RNN在TF中的实现
Embedding层在 TensorFlow 中,可以通过 layers.Embedding(𝑁_vocab,𝑛)来定义一个 Word Embedding层,其中𝑁_vocab参数指定词汇数量, 𝑛指定embedding后的单词向量的长度
1import tensorflow as tf
1234567#这里应该是对一个句子而言x=tf.range(10)#生成10个单词的数字编码:[0,9]x=tf.random.shuffle(x)print(x)#创建10个单词,每个单词用长度为4的向量表示net=tf.keras.layers.Embedding(10,4)#10是单词个数,4是embedding后的向量长度out=net(x)
tf.Tensor([1 0 8 9 3 4 5 6 2 7], shape=(10,), dtype=int32)
(10,4)是一个句子的单词个数和embedding后的向量长度,若有NUM个句子,则shape变为(NUM,10,4)
12#Embedding层内部的查询表tablenet.embeddings
<tf ...

元组与集合-Python基础连载(十一)
开篇
在本期内容中,将介绍Python六大标准数据类型中最后两种:元组(tuple)与集合(set)。
元组(tuple)你已经学习过列表,并且知道列表是可变数据类型。这里要学习的元组和列表非常相似,在掌握列表的使用方法基础之上,再来学习元组会非常容易。
你只需记得元组与列表的不同之处:
1.元组是不可变数据类型
2.元组使用()包裹元素
元组的不可变特性决定了元组没有增删改等功能,只可查询。
其查询方法归纳如下:
1. index()
()内传入所要查询的元素值,返回该元素值所在的下标,若找不到该元素值,则报错:
1234>>> x=(1,2,3,4,5)>>> x.index(2)#查找元素2对应的下标1>>> x.index(2333) #2333不在x中,因此报错Traceback (most recent call last): File "<pyshell#50>", line 1, in <module> x.index(2333)ValueError: tupl ...

记忆中的那座房子
我又来到了记忆中的那所房子昏黄的傍晚,在东边那个小房间里,有几个人人嗑着瓜子,看着电视我认出了他们其中一人,其余人似曾相识,可却无法看清他们的面容时间一分一秒的流逝着…他们一直在那里,嗑着瓜子,看着电视潮湿的空气使我感觉到呼吸困难于是我走出房门,来到院子里抬头环顾天空,只见西南上空被墨汁浸染视线在晃动,墨汁在扩散又是一场逃不掉的大雨它伴随着夜色的临近而逐渐肆虐我从院子踱步至大门底下,拿了个马扎坐下,静静地等待着许久,耳畔清净了我看了下手机,晚8点透过东边房间的窗户,我看到暗蓝色的光影闪烁着,并时不时的传出豆子爆裂的声音据此推断 他们应该还在看着电视,磕着瓜子吧我打开手机的灯光,推开大门按理说刚下过雨,门前这条年久失修的土路应该是非常泥泞的,可现在却一点也看不出来我试探着踩上去我相信自己的感觉了我举起手机,向这条路的前方照去可灯光微弱,被黑夜吞噬在前方三米处我索性关了手机的灯光,使视线接受到的画面范围更加广阔我隐隐约约看到了那棵大榆树于是向前走去“小心!”只见一个黑影向我扑来在这个黑夜,我看不清ta的样子,也分不清ta是人还是其他活物,所以只是大致看出一个黑影我立即躲到大榆树后面,距 ...

捉迷藏
捉迷藏的游戏,一望无际的麦田那时夕阳未落,一群人藏,一个人找闭上双眼,在另一个时空重复阿拉伯数字,98,99,100…暗伏于柳后,栖身高草丛 ,躲避找寻的目光被草木包围着是安全的,至少心理上是透过些许缝隙,窥探外面的世界找寻的人在找寻,石头后,小桥底脚步声愈发近了高草丛中,屏住呼吸蛙鸣,蝉鸣似是天外之音而世界死寂又是许久,窸窸窣窣的鞋子与草地摩擦声渐行渐远不远处,夕阳将被吞噬风起,但无济于事紫色的油纸伞,撑在天空中循着找寻者的身影,我看向那片麦田画面开始模糊,而声音愈发清晰游戏似乎结束了,我起身离开那片草丛,向他们走去画面更加模糊了,声音开始撕裂我捂住耳朵快步走上前去那片麦田开始变得耀眼之后画面消失当我再次想看向麦田的方向时,却发现自己站在路灯下,重复着“一群人藏,一个人找”的游戏黯淡的白色冷光下,一群飞舞的虫蛾随后,灯光灭了虫蛾不知所踪,也许是加入了游戏吧后来,找寻者抱怨了几句意思大概是夜太黑,没有灯光,难以找寻的确是这样于是我打开那把随身携带的老旧手电,从找寻者的身后向前照去不过手电的微光瞬间被黑暗侵袭我终于赶在了找寻者的前面围绕着猜测其余人的躲藏位置,我们有一搭无一搭的聊着我随 ...
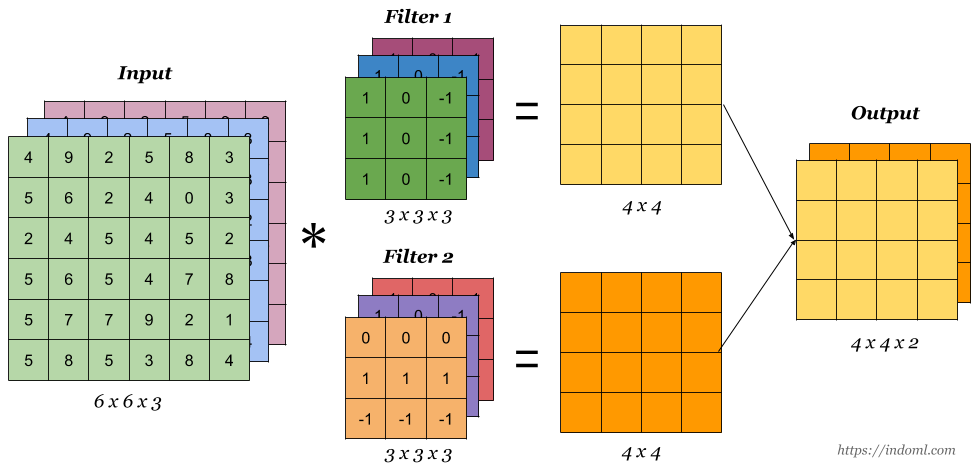
TF中的卷积层实现
tf.nn.conv2dtf.nn.conv2d函数用于实现2D卷积运算
输入X:[b,h,w,cin]
卷积核W:[k,k,cin,cout]
输出O:[b,h',w',cout]
其中,cin表示输入通道数,cout表示卷积核的数量,也是输出特征图的通道数
卷积核大小为k*k
123456import tensorflow as tfx=tf.random.normal([2,5,5,3])#模拟输入,3通道,高宽为5,2张图片#需要根据[k,k,cin,cout]格式创建 W 张量(filter), 4 个 3x3 大小卷积核w=tf.random.normal([3,3,3,4])#步长为1,padding为0out=tf.nn.conv2d(x,w,strides=1,padding=[[0,0],[0,0],[0,0],[0,0]])
1print(out.shape)#2是2张图片
1TensorShape([2, 3, 3, 4])
2代表2张图片,3*3便是卷积(步长为1,padding为0)之后的图像大小,4是代表用4各卷积核作用。下图以其中一 ...

字典,寻寻觅觅-Python基础连载(十)
开篇
以前在查阅纸质字典时,有一种音序查字法,可以根据汉字的拼音将查询范围缩小到几页纸中,然后逐页查找目标字。也就说,一个拼音可以对应多个汉字。
本期所讲的字典数据类型,也是根据某种东西(key)去查询另一种东西(value),但与上述过程稍微有些不同,至于不同之处嘛,我写在文中咯。
需要说明的是,字典中的许多方法名都类似于列表中的方法名,大家可以对比着学习,同时也不要搞混了哦~
让我们开始吧!
初识字典字典用{}包裹,比如d={'name':'Bob','age':13,'gender':'male'}便是一个字典:
观察上面的字典d,可以归纳出字典的基本结构:
12:`前面的被称为`key`(键),比如`'name':`后面的被称为`value`(值),比如`'Bob'
键和值合起来被称为一个键值对,比如'name':'Bob'
各个键值对之间用逗号,分隔开。
可以根据key来查找对应的v ...

缺失的记忆
和往常一样,我坐在教室,铃声不知何时响起的,只看到班主任走了进来“翻开你们的练习册,平摊在课桌上”,班主任一边说着,一边从左前方开始检查我翻开了,映入眼帘的是一堆语文填空,并且上面还有写过的笔迹奇怪,在我的记忆中,他是HX老师我问旁边的同桌Z,Z也不知为何,只得苦笑一声我愈发感到奇怪班主任离我所在位置越来越近,而我和Z仿佛着了魔似的,盯着那些填空题“你们的呢?”他已经来到了我的书桌前Z似乎反应了过来,说我们做的不是练习册,而是另一本习题册,一边说着,一边将之前看到的带填空的那一页展开可是,那里是一片空白按理说,现在班主任应该发火,怒斥我们可是并没有,他只是楠楠的说了几句,便继续检查下一位了我疑惑的翻开练习册和习题集,这次没错了,是HX题,之前的语文填空题就好像从未存在过一样突然,身后传来拖鞋与地板摩擦的声音,只见一个同学走到了班主任面前他抱住班主任,和另一个同学一起想把班主任撂倒这是要打架啊虽然班主任平时并不怎么讨人欢喜,可是这种情况也是不应该发生的啊我见状不对,而且自己现在又是离班主任距离最近,于是上前去,与他们抗衡后面的记忆却消失了画面的下一帧,放学了走出校门(其实不知 ...

高层API:Keras
常见功能模块常见网络层类tf.keras.layers类中包含了全连接层、 激活函数层、 池化层、 卷积层、 循环神经网络层等常见网络层的类,可以直接使用这些类创建网络层,这里以softmax为例:
123import tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers#导入常见网络层类
123x=tf.constant([2.,1.,0.1])layer=layers.Softmax(axis=-1)#创建softmax层out=layer(x)#调用softmax前向计算,输出为out
1out
<tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.6590012 , 0.24243298, 0.09856589], dtype=float32)>
当然,也可以使用tf.nn.softmax()函数计算
1out=tf.nn.softmax(x)
1out
<tf.Tenso ...
反向传播案例实战
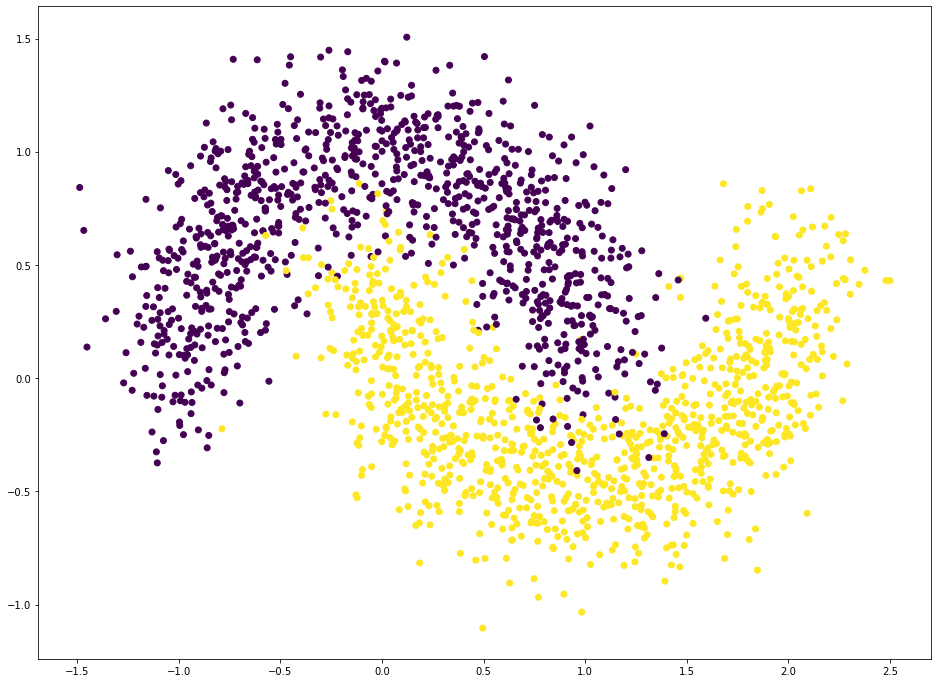
说明我们将实现一个 4 层的全连接网络,来完成二分类任务。 网络输入节点数为 2,隐藏层的节点数设计为: 25、 50和25,输出层两个节点,分别表示属于类别 1 的概率和类别 2的概率,如下图所示
生成数据12from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split
123N=2000test_size=0.3X,y=make_moons(n_samples=N,noise=0.2,random_state=100)
划分训练集和测试集1X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=test_size,random_state=42)
1print(X.shape,y.shape)
(2000, 2) (2000,)
数据可视化1234import matplotlib.pyplot as pltplt.figure(figsize=(16,12))plt.scatt ...
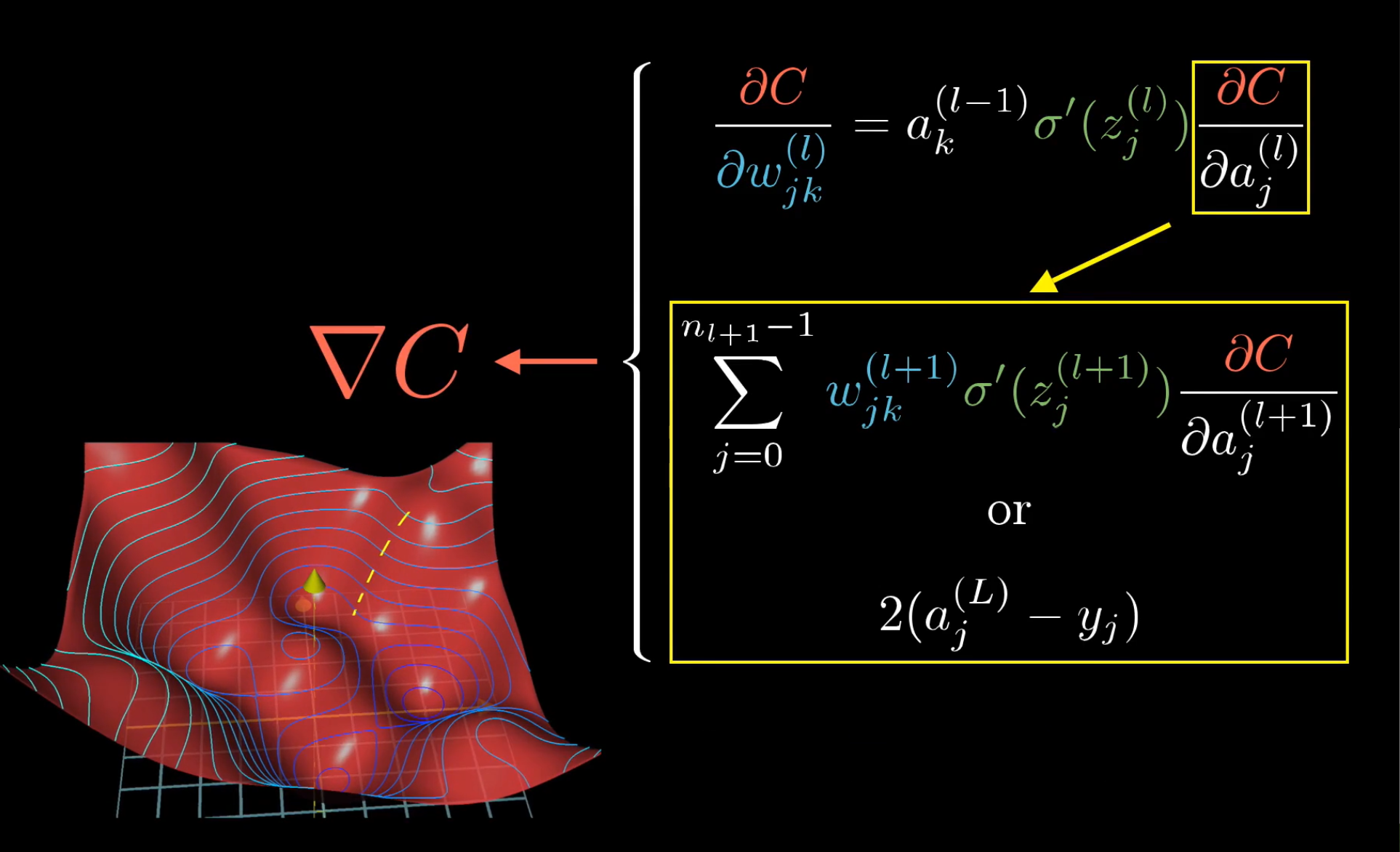
反向传播算法推导
每层只有一个神经元
我们的目标是调整这些参数,使得代价C最小
这里以后两个神经元为例进行演示
首先推导代价函数关于权重w的偏导数
其中上标(L)代表第L层
$w^{(L)}$的的微小扰动会影响$z^{(L)}$,同样$z^{(L)}$的微小扰动会影响$a^{(L)}$,从而最终影响到代价值
它们之间的影响是通过链式法则传递的
现在来求解以上各个偏导数
当样本量不止一个时,则总的代价函数是许多训练样本代价的总和平均值
当然,对于多层的神经网络来说,以上所求仅仅是梯度中的一个分量
对于偏置项同样有以下推导
也可以求出代价函数对于上一层激活值的敏感度
主要是$z^{(L)}$对上一层的敏感度,其余不动
每层有若干神经元依然用上标括号内的数字代表第几层,同时用下标i和j分别标注第(L-1)层和第(L)层的神经元
在上图中,第L-1层有3个神经元,记连接第k个神经元和第j个神经元的(权重)连线为${w_{jk}}^{(L)}$
与之前的单个神经元相比,此时有3个神经元,因此代价函数是每一个神经元的代价值之和,每一层的权重个数也由一个:$w^{(L)}$变为3个:${w_{j0 ...

